library(tidyverse)library(here)library(knitr)library(rriskDistributions) # to fit distributionslibrary(RColorBrewer)library(msm) # for truncated normal library(gt) # for complex tableslibrary(MASS) # for colinaritylibrary(tibble)library(dplyr)library(tidyr)library(MASS)library(ggcorrplot)library(patchwork)conflicted::conflicts_prefer(dplyr::filter)
Show the code
set.seed(1991)
5.1 Objective
Show the code
n_patient <-625# number of patients simulated per cohort
Show the code
here::i_am("Simulations/covariate_simulation.qmd")# Create folder to store published figuresif (!dir.exists(here("Figures"))) {dir.create(here("Figures"))}cov_data <-read_csv(here("Simulations/cov_distrib_from_papers.csv"))
From each identified paper, we want to simulate a cohort of patients. For each cohort we want to simulate 625 patients. We define a patient by a vector of covariate values. The covariates of interest are :
WT : Body weight (kg)
CRCL : Creatinine clearance (mL/min)
ICU : Is the patient an ICU patient (=1) or not (=0)
BURN : Is the patient a burn patient (=1) or not (=0)
OBESE : Is the patient a obese - BMI > 30 kg/m^2 (=1) or not (=0)
SEX : Male (=0) or female (=1)
HT : height (cm)
AGE : age (years)
To simulate covariate values we use information on the distribution of the covariates taken from the included papers.
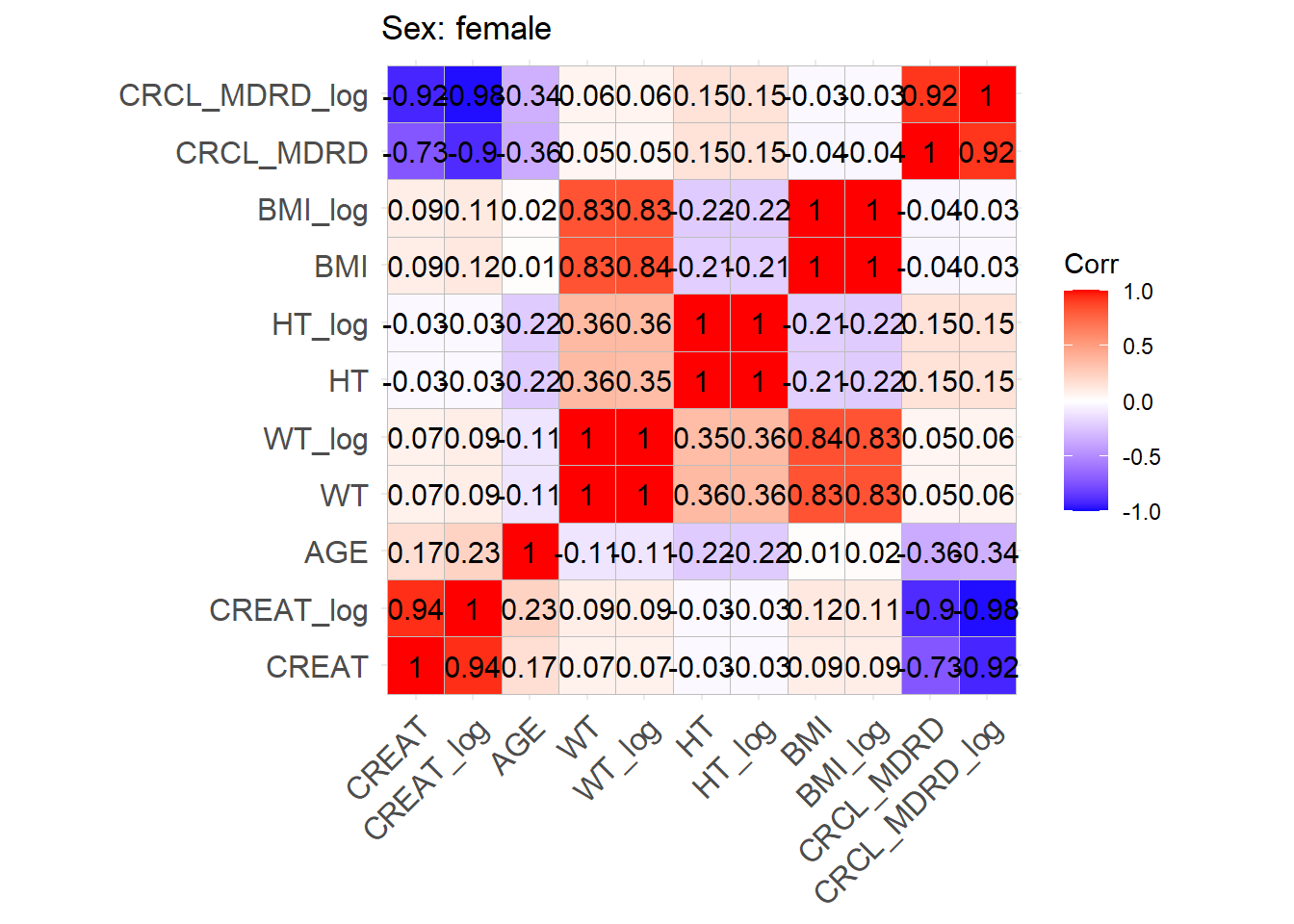
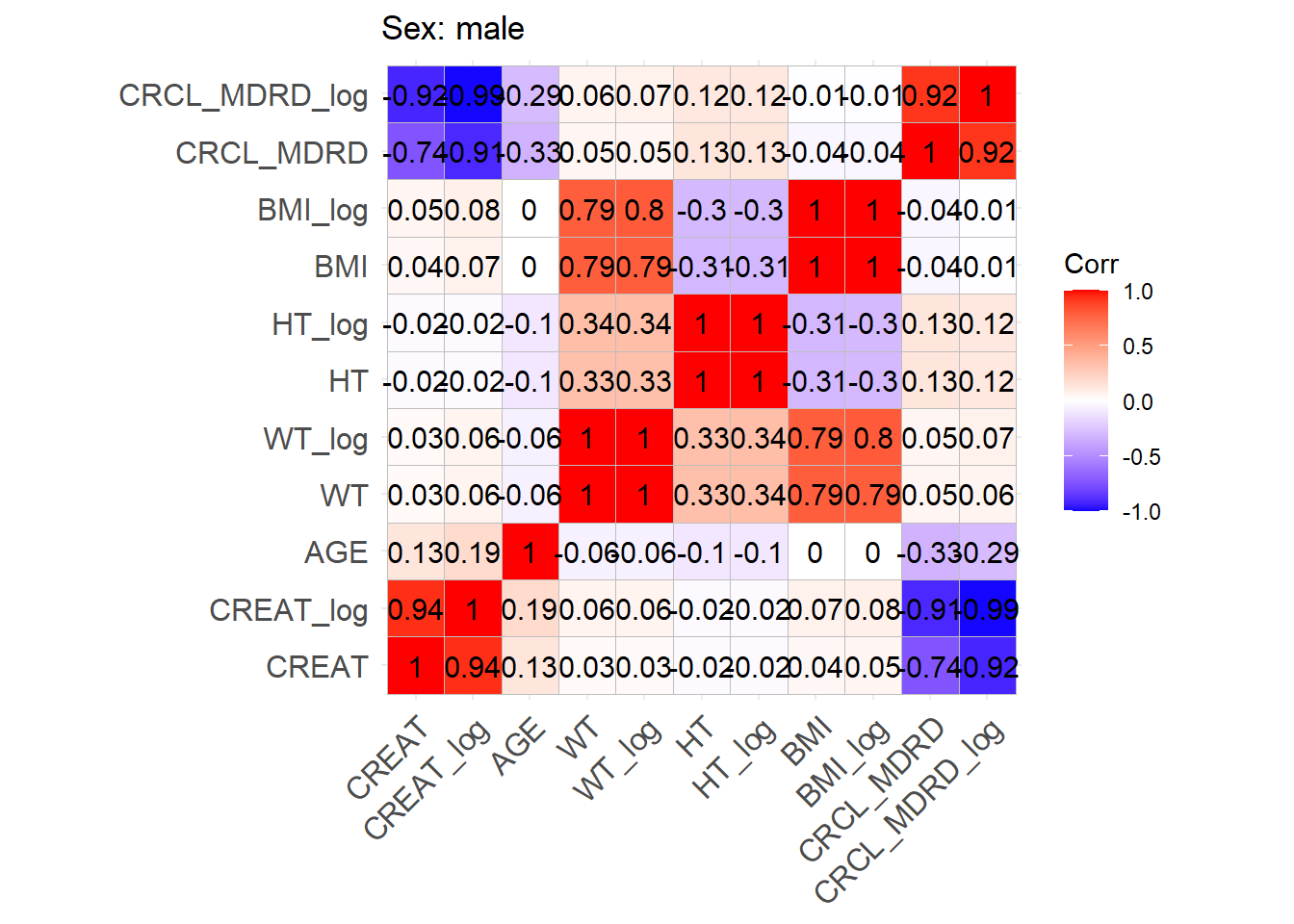
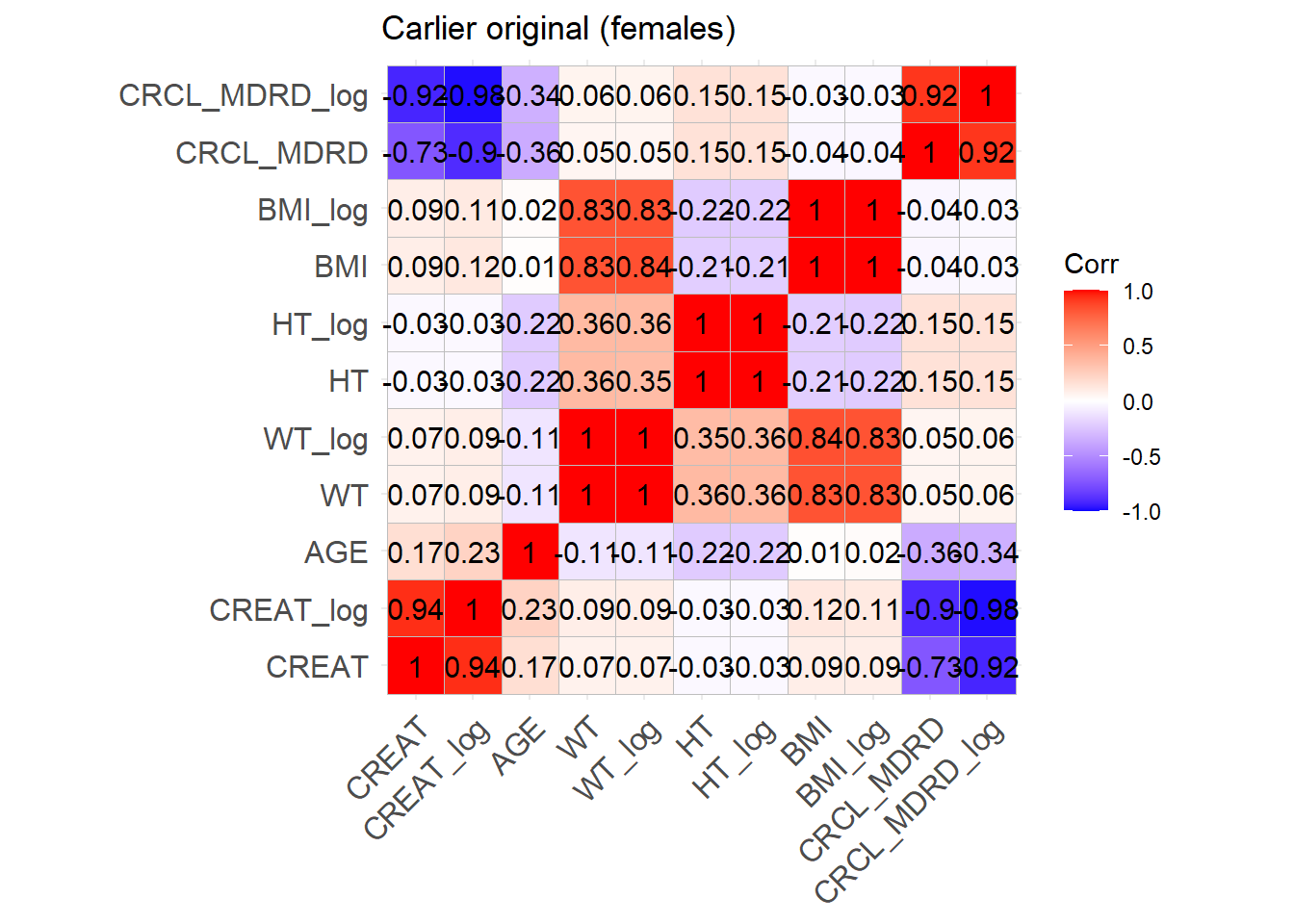
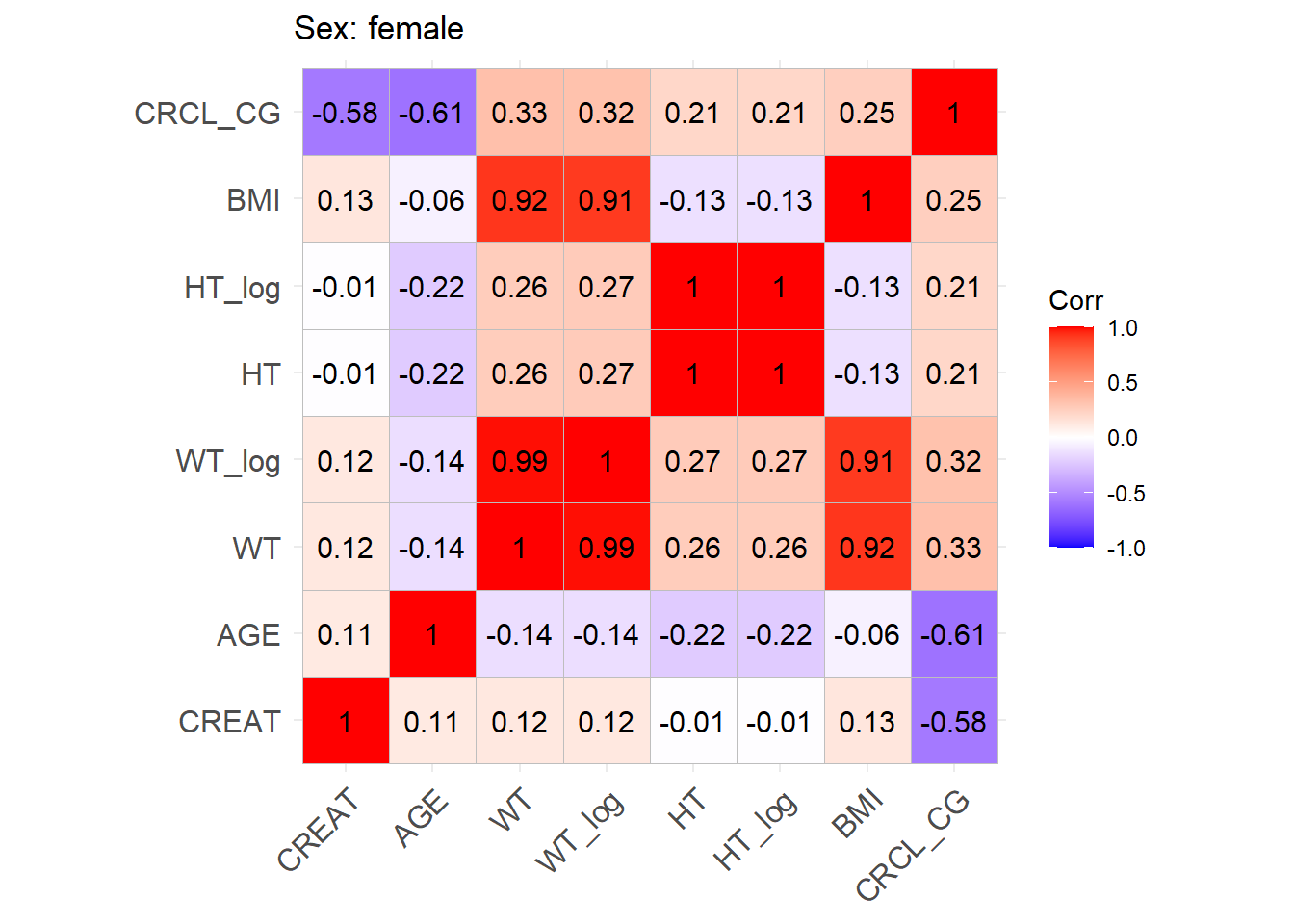
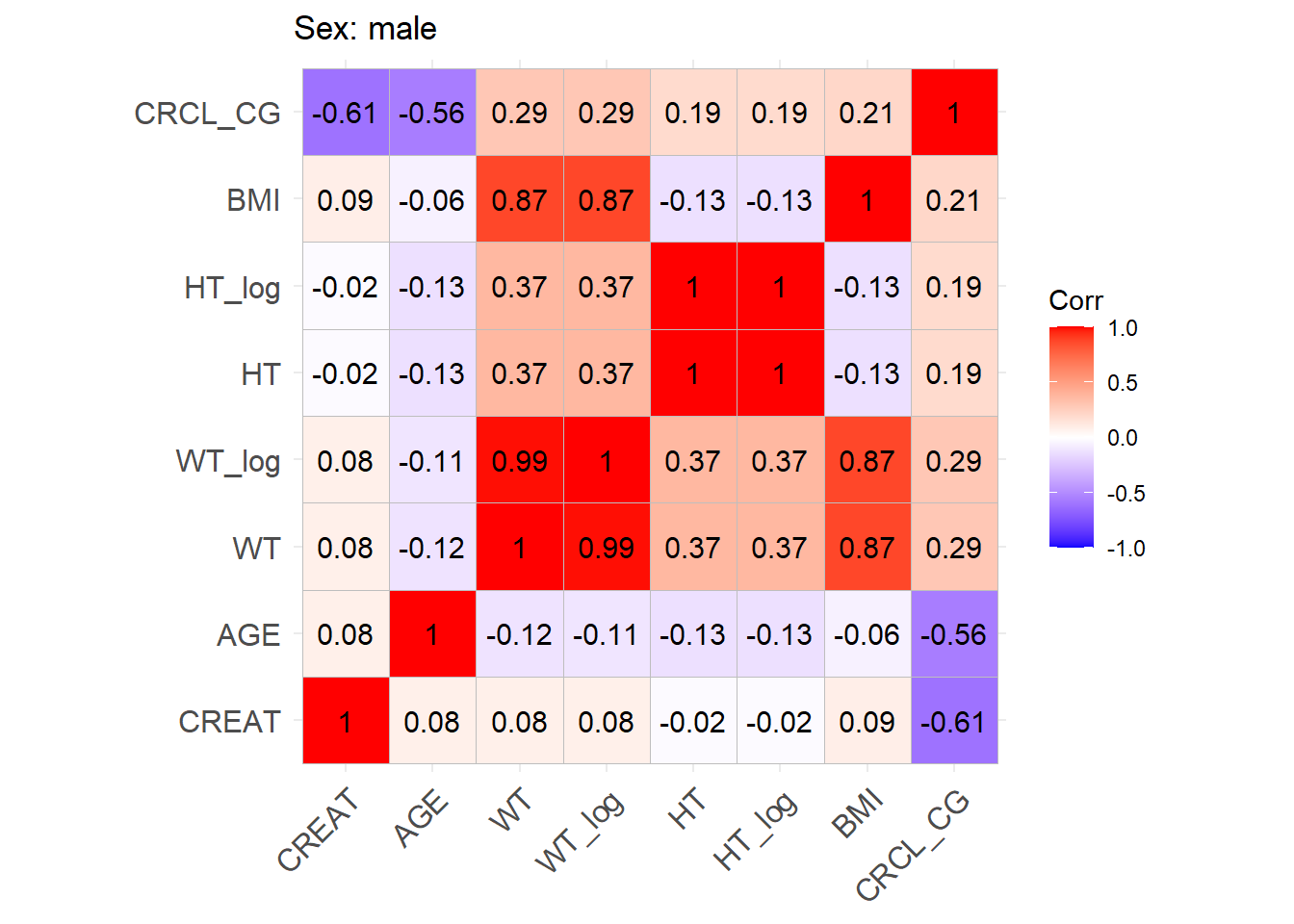
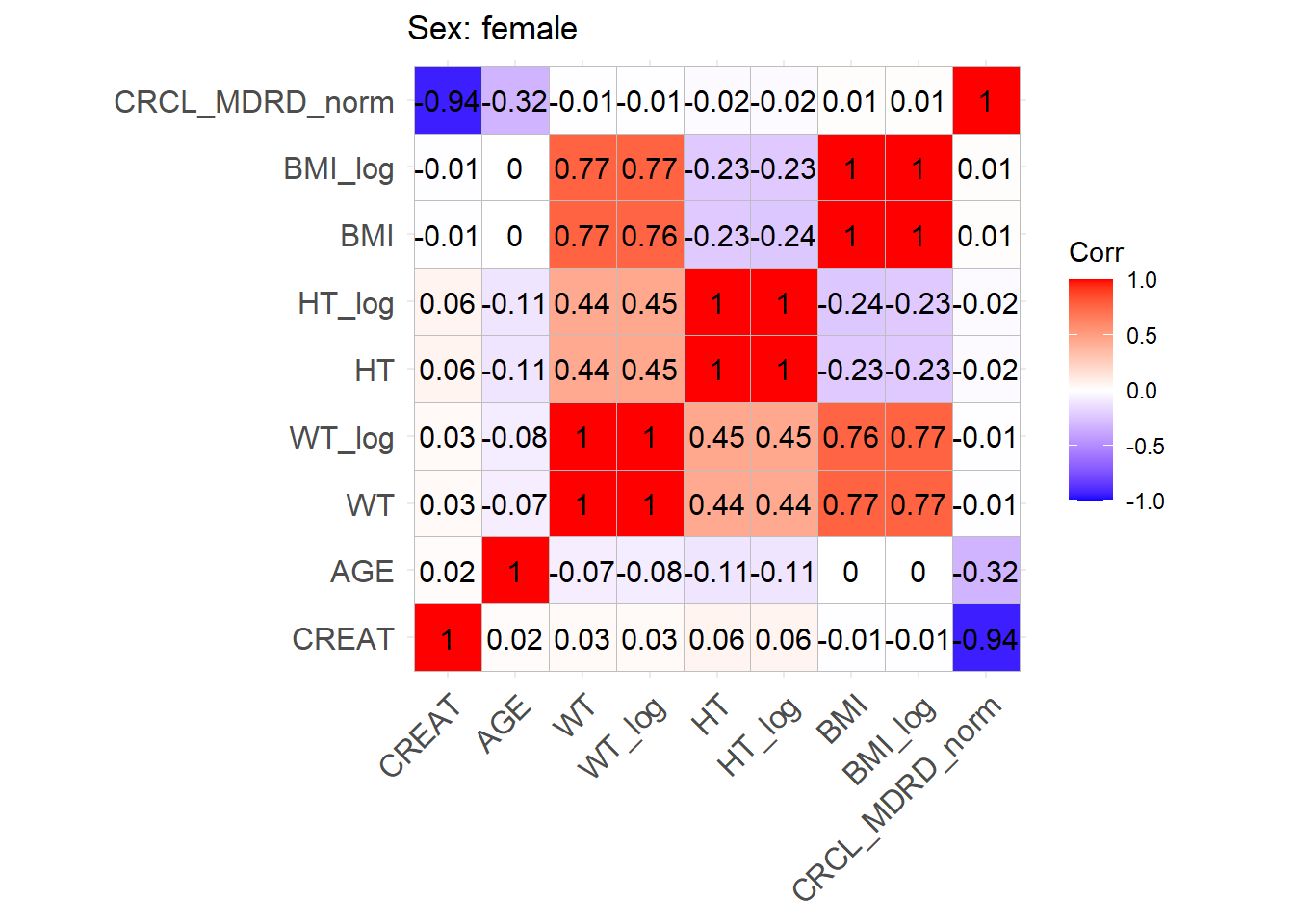
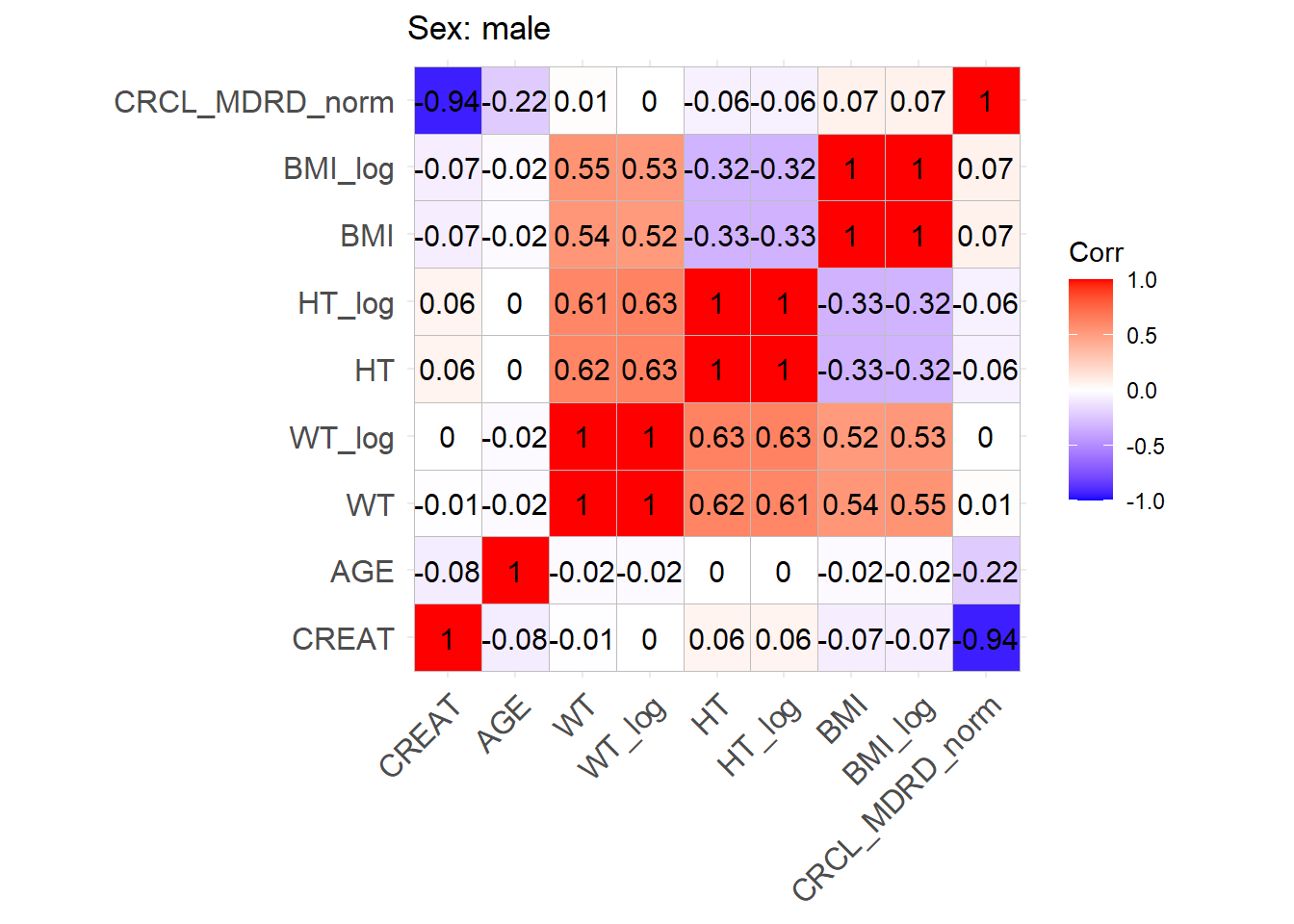
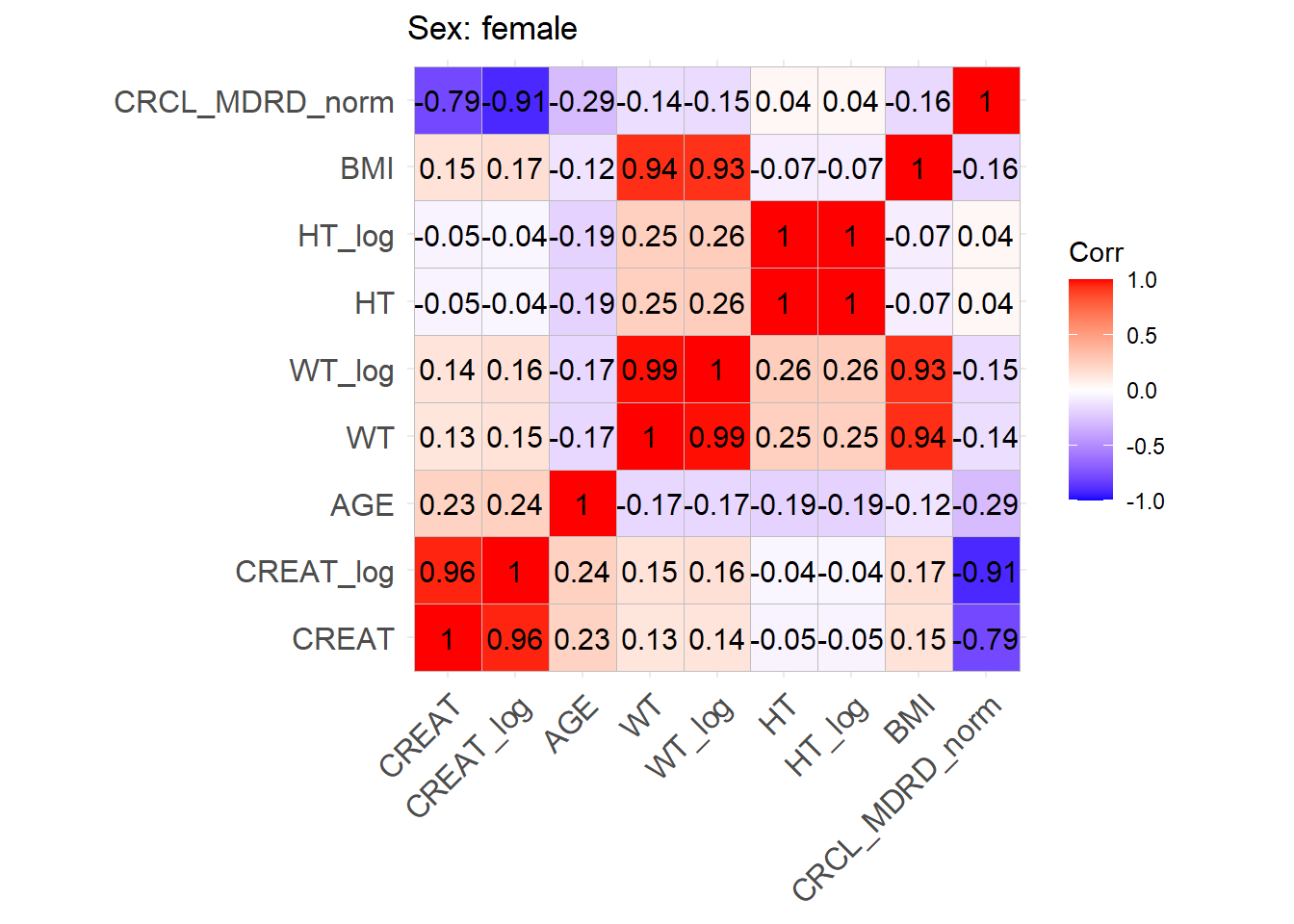
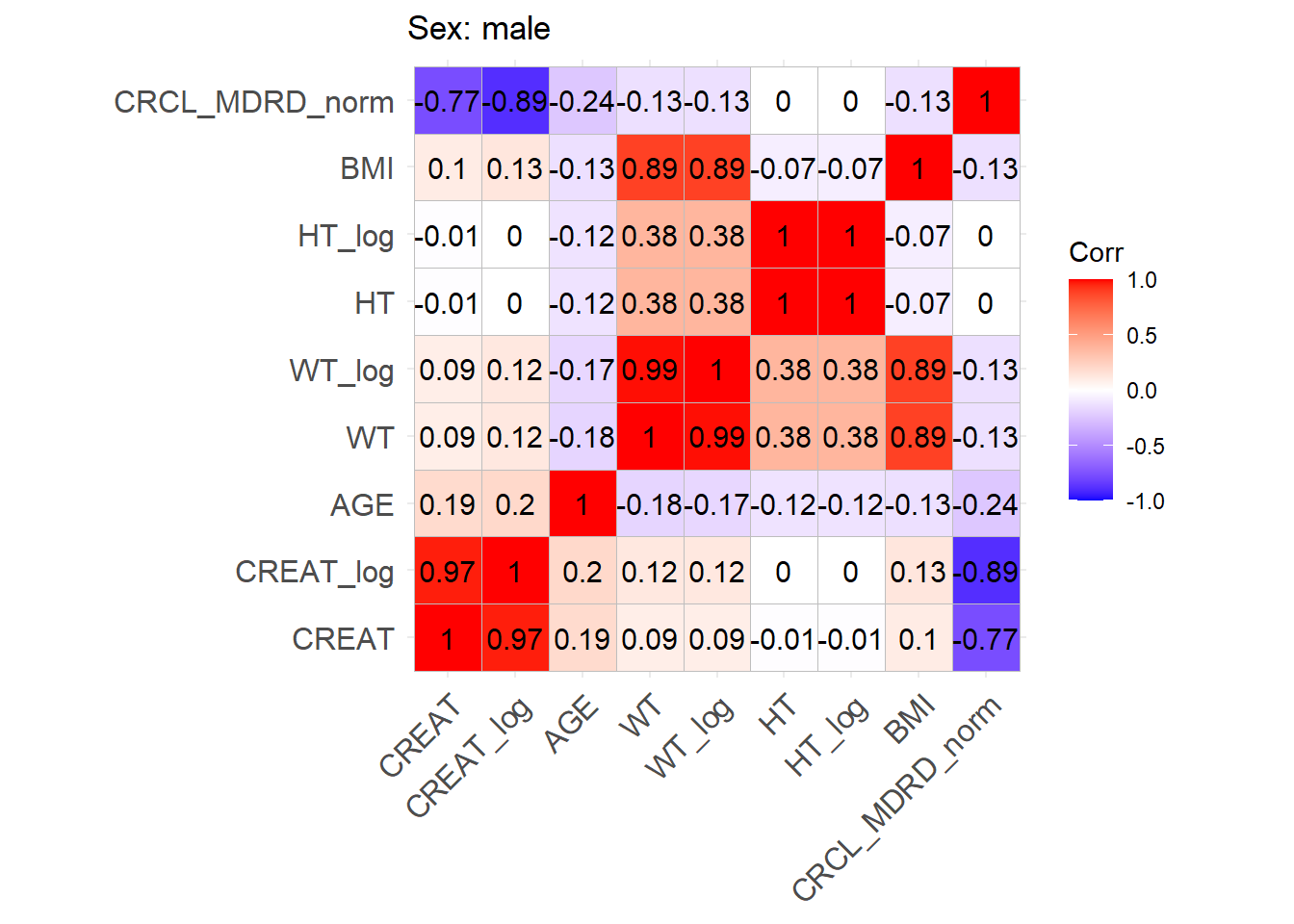
One issue with the covariate data reported in these papers is that correlations between covariates are not reported and simulating without correlations runs the risk of simulating improbable covariate values. We thus obtained a clinical dataset composed of more than 16000 ICU patients (Johnson et al. (2023)) from which we could derive correlations between covariates of interest. Age, serum creatinine, body weight, sex, height and BMI were obtained for these patients and the creatinine clearance was calculated (in mL/min for Cockroft and Gault and CKD-EPI and in mL/min/1.73 m2 for MDRD (to correspond to Mellon)). A correlation matrix was calculated for each of the respective model development cohorts separately for females and males.
This correlation matrix is used to simulate correlations between the simulated WT, CRCL, AGE, and HT/BMI if necessary to convert CRCL to serum creatinine. (CRCL_MDRD_norm means CRCL in mL/min/1.73 m² used for Mellon and CRCL_MDRD in mL/min.). Different correlation matrices are used based on sex. This way two different mutltivariate distributions are simulated based on the two matrices with a number of patients that respects the original article proportions.
We can find correlations for the log-transforms of certain variables. For the covariates where a log-normal distribution fits better the log mean and standard deviation of this distribution will be used to sample log values with a multivariate normal distribution. At the end, the log variables will be retransformed to normal ones.
All patients are ICU patients and we will assume that they are not burn and not obese patients. Creatinine clearance was obtained using the measured urinary equation. Thus for all patients ICU = 1, BURN = 0.
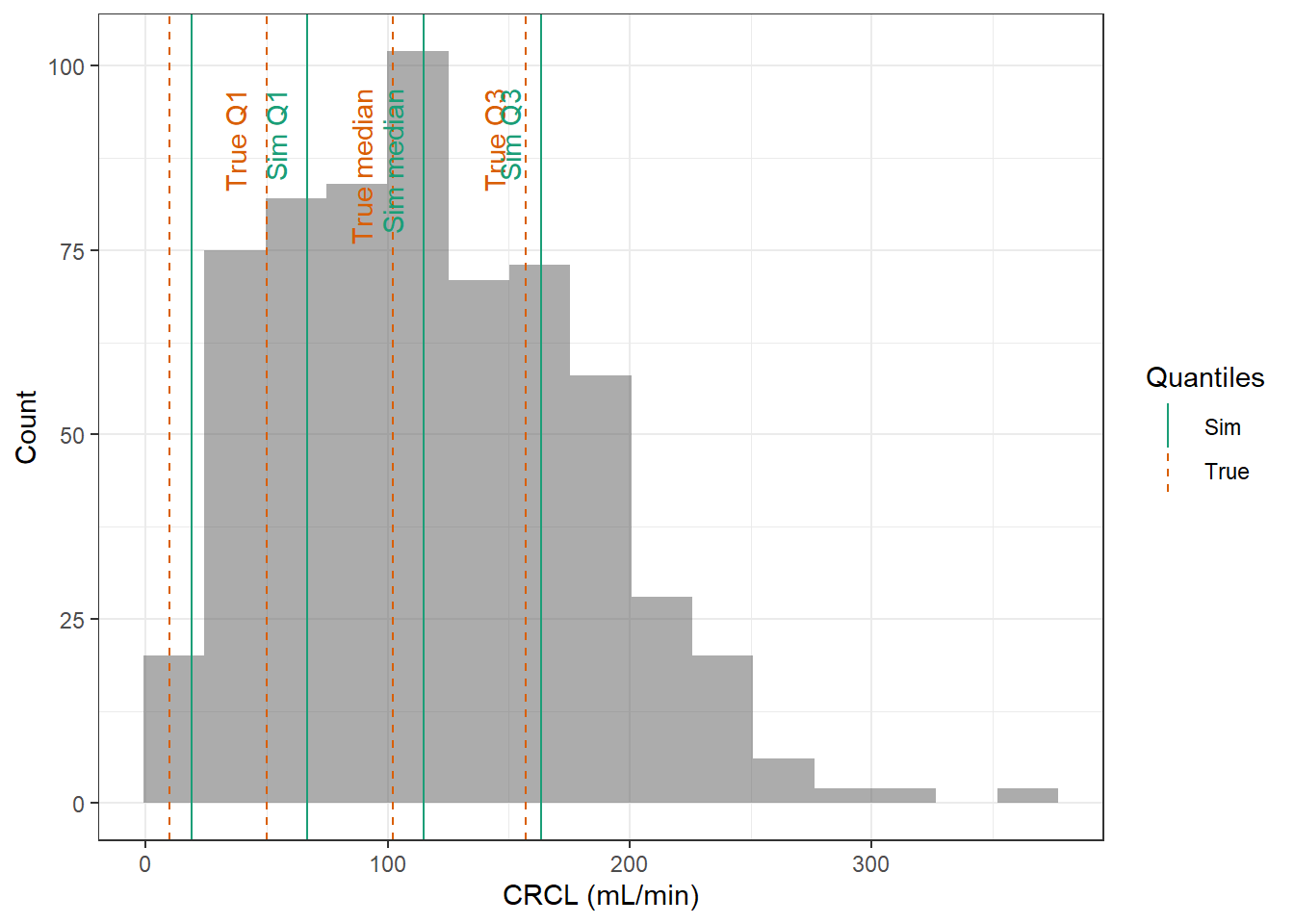
As discussed in the article, renal replacement therapy is an exclusion criterion, therefore the minimum value of creatinine clearance is set to 10 mL/min, any simulated value below 10 mL/min will be resampled. CRCL was calculated using the measured urinary equation.
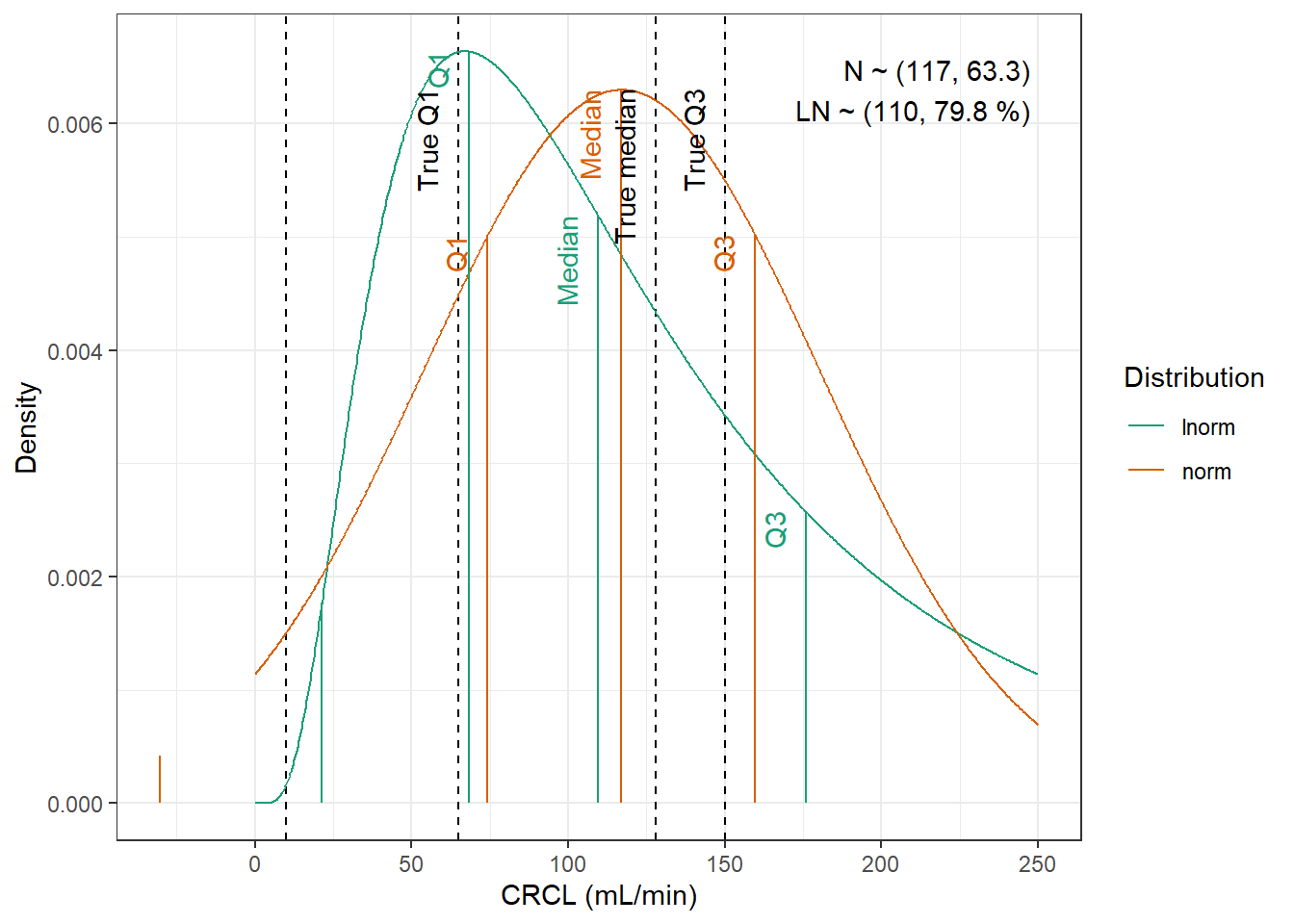
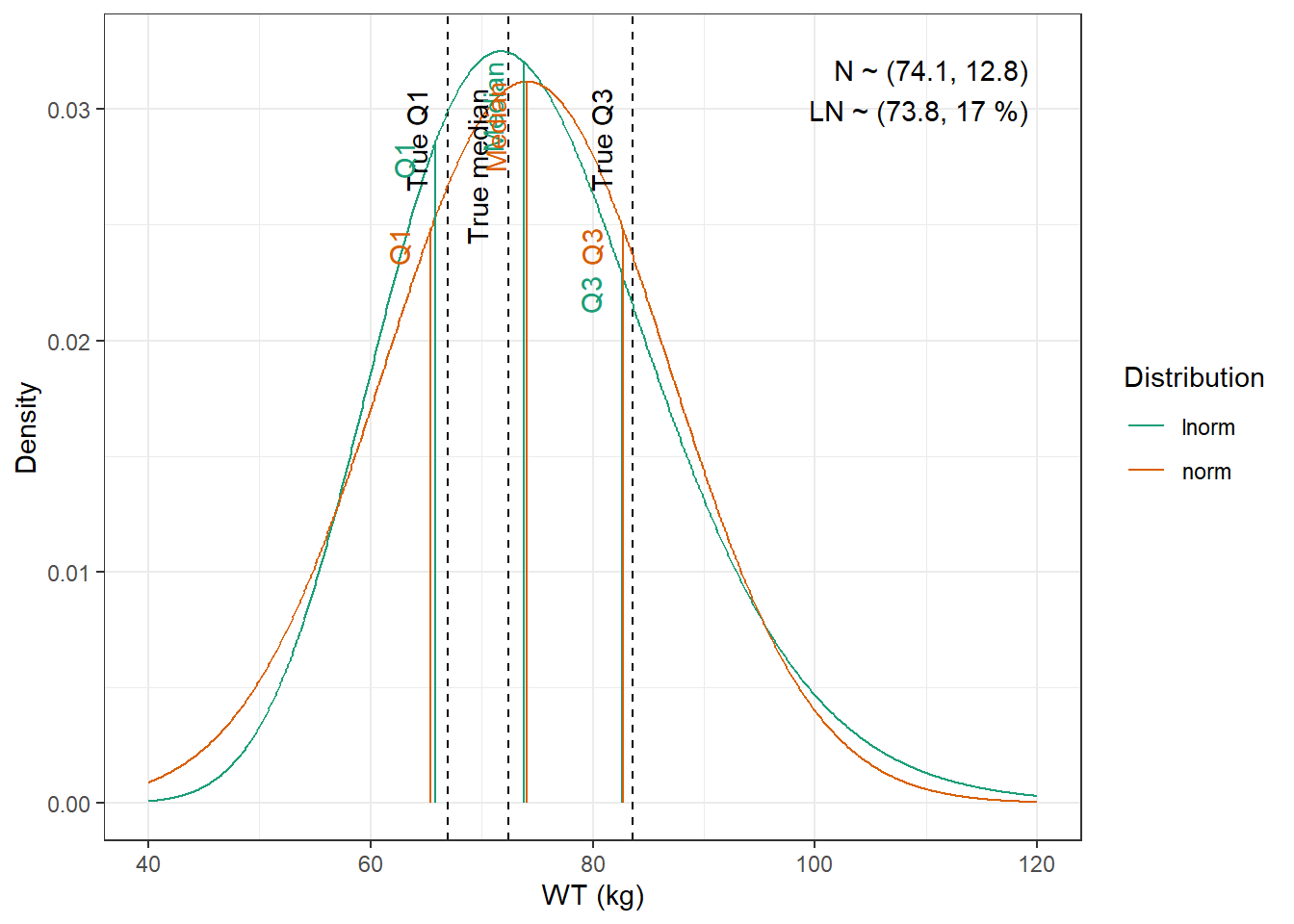
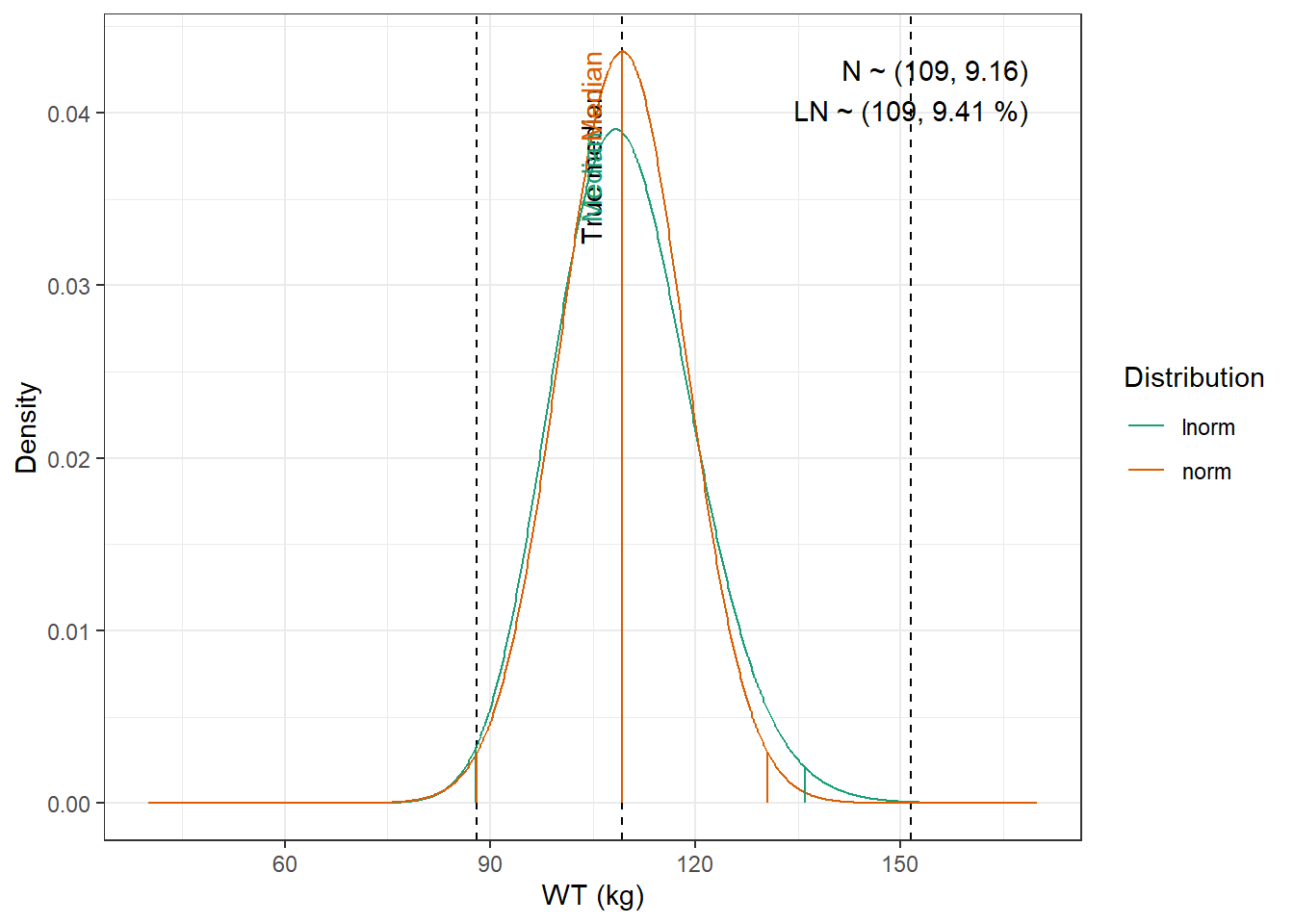
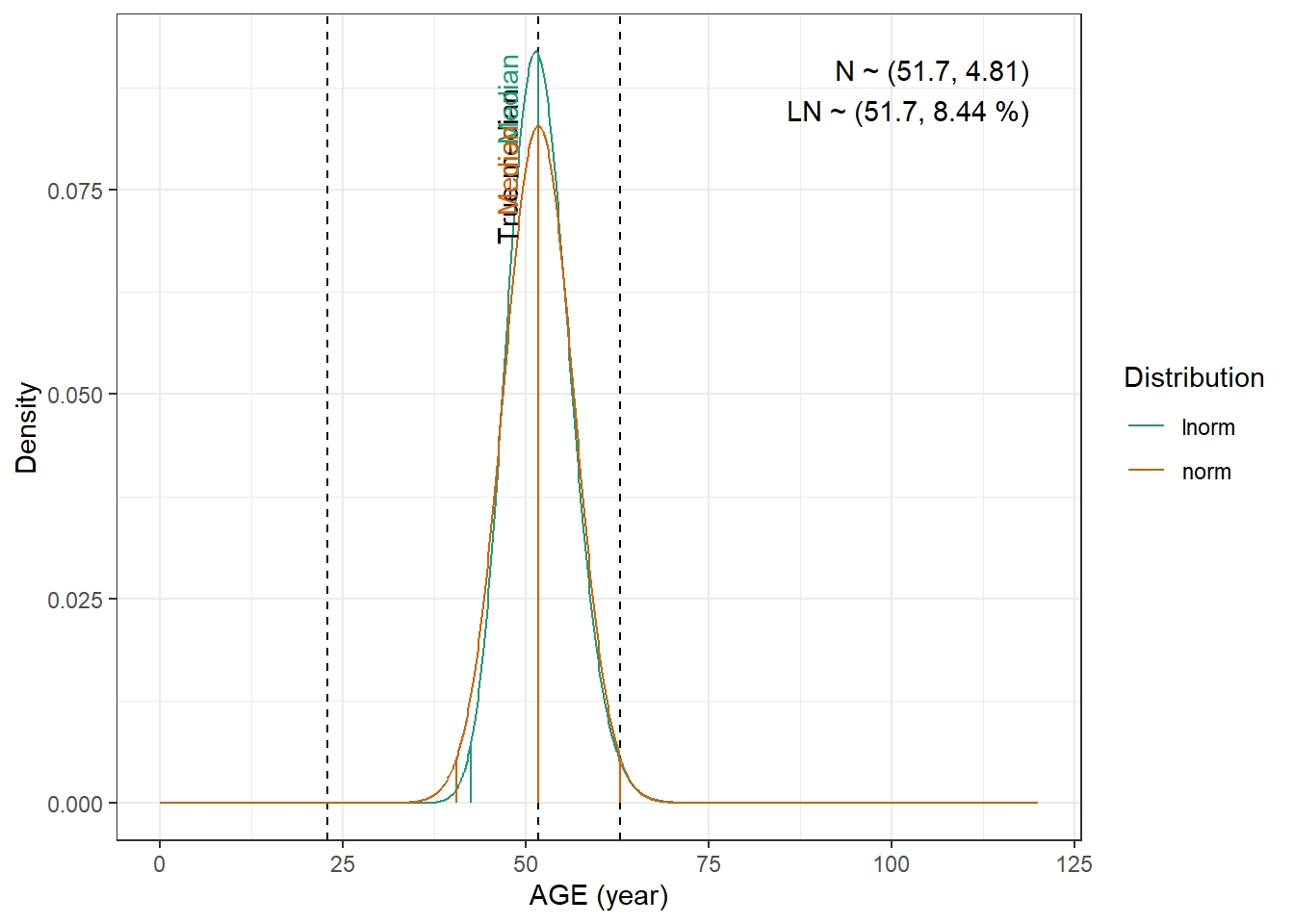
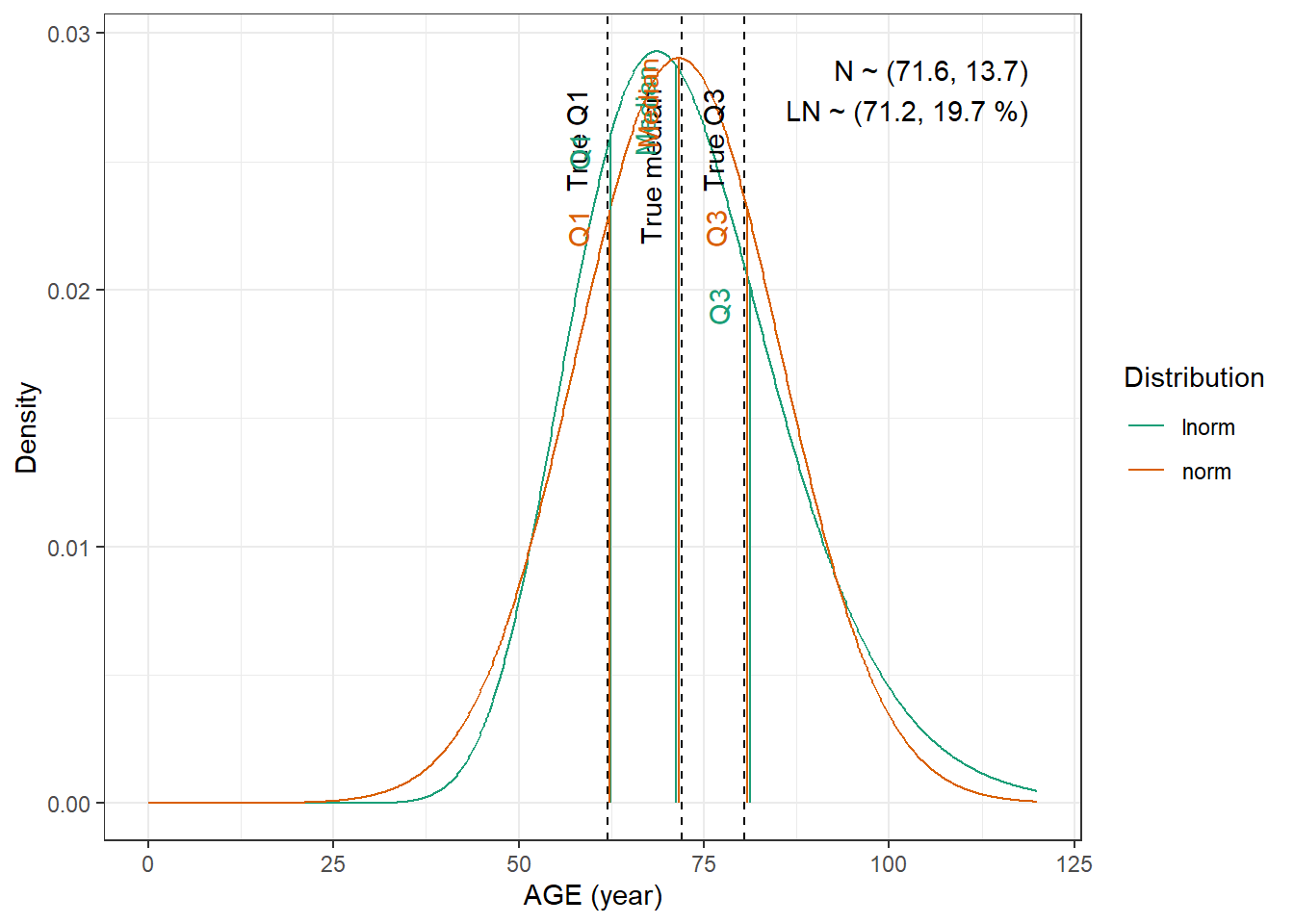
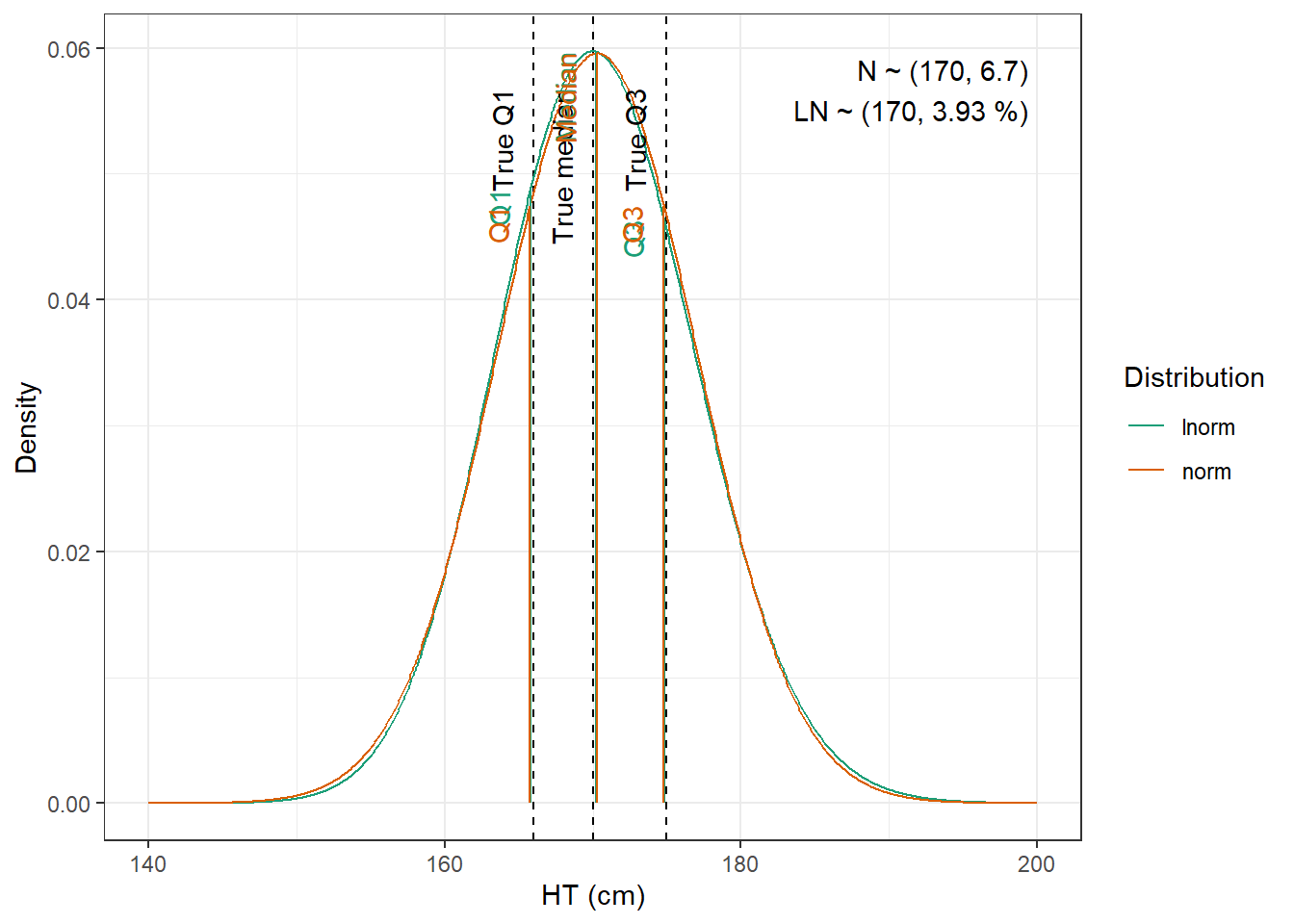
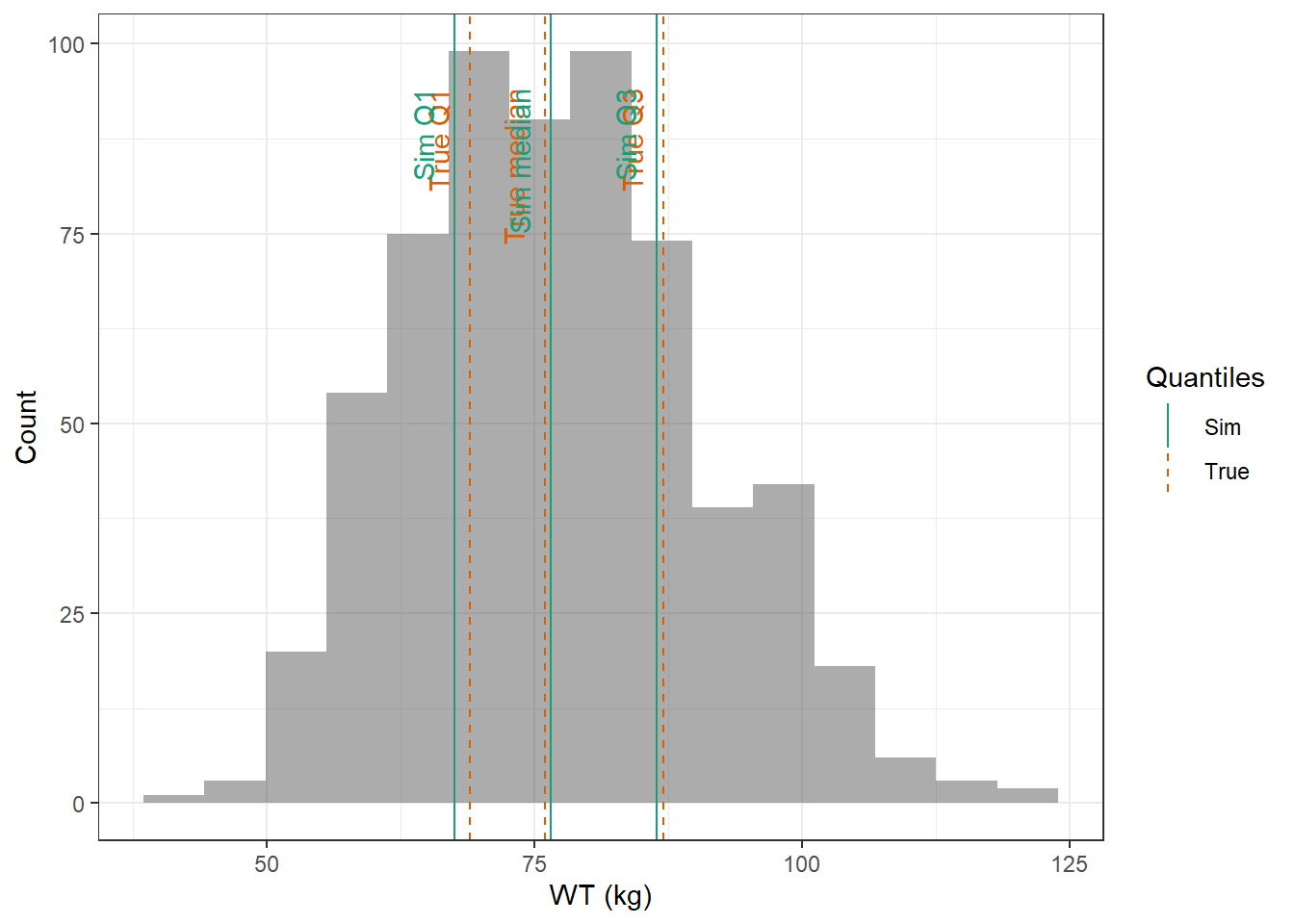
For WT and CRCL here are the data from the paper :
ggcorrplot(cor_matrix_Carlier_M, lab =TRUE, title ="Sex: male")
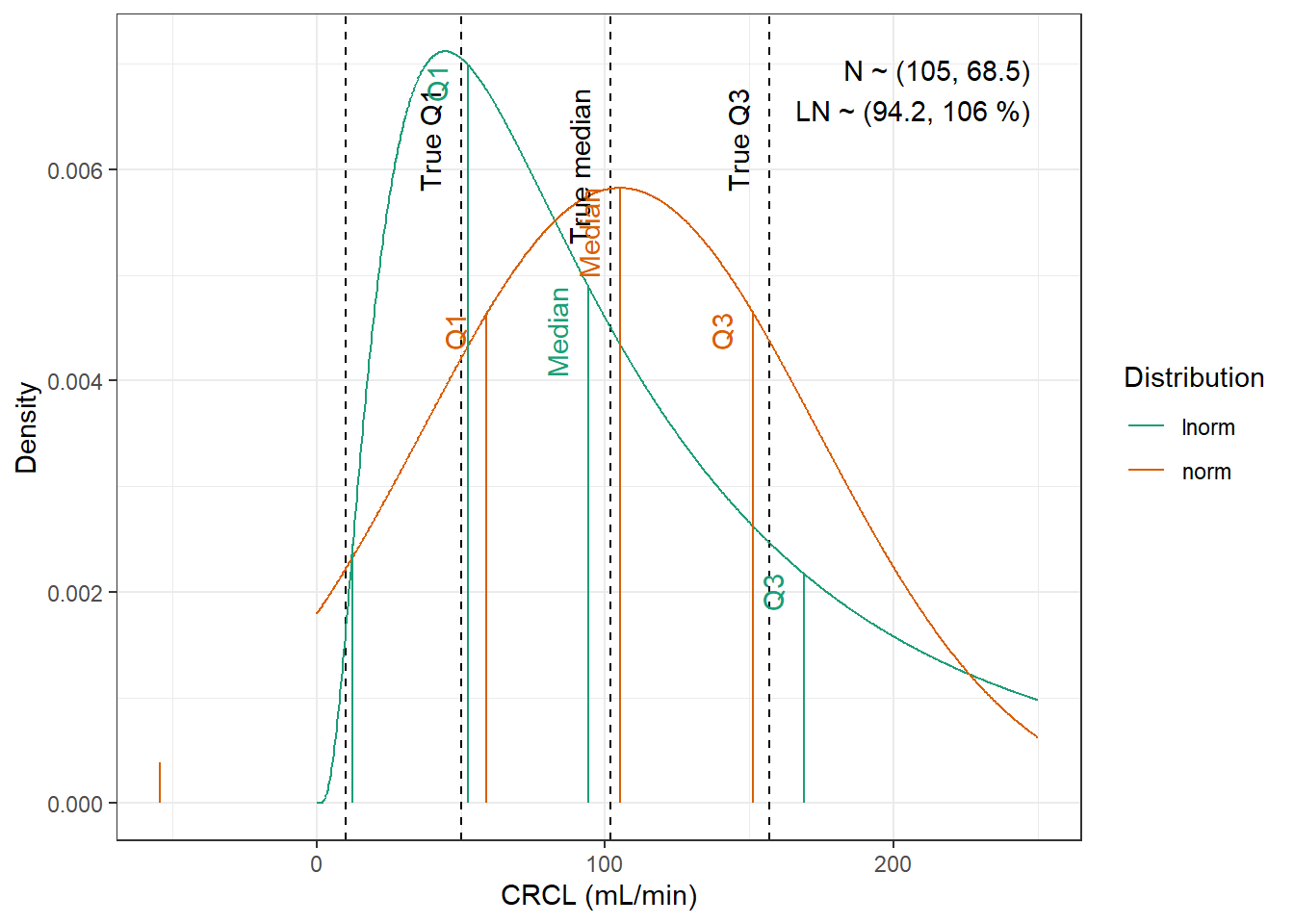
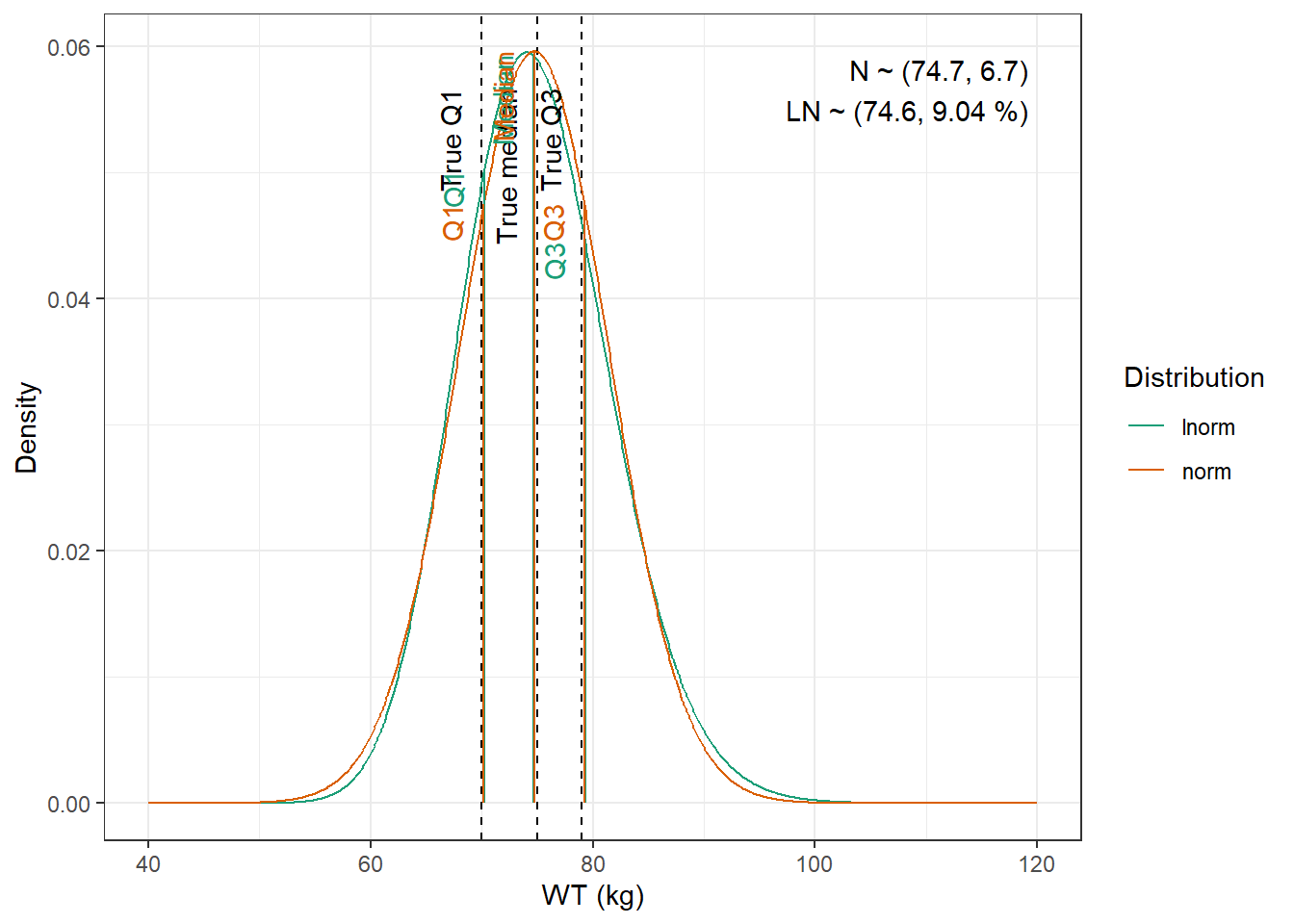
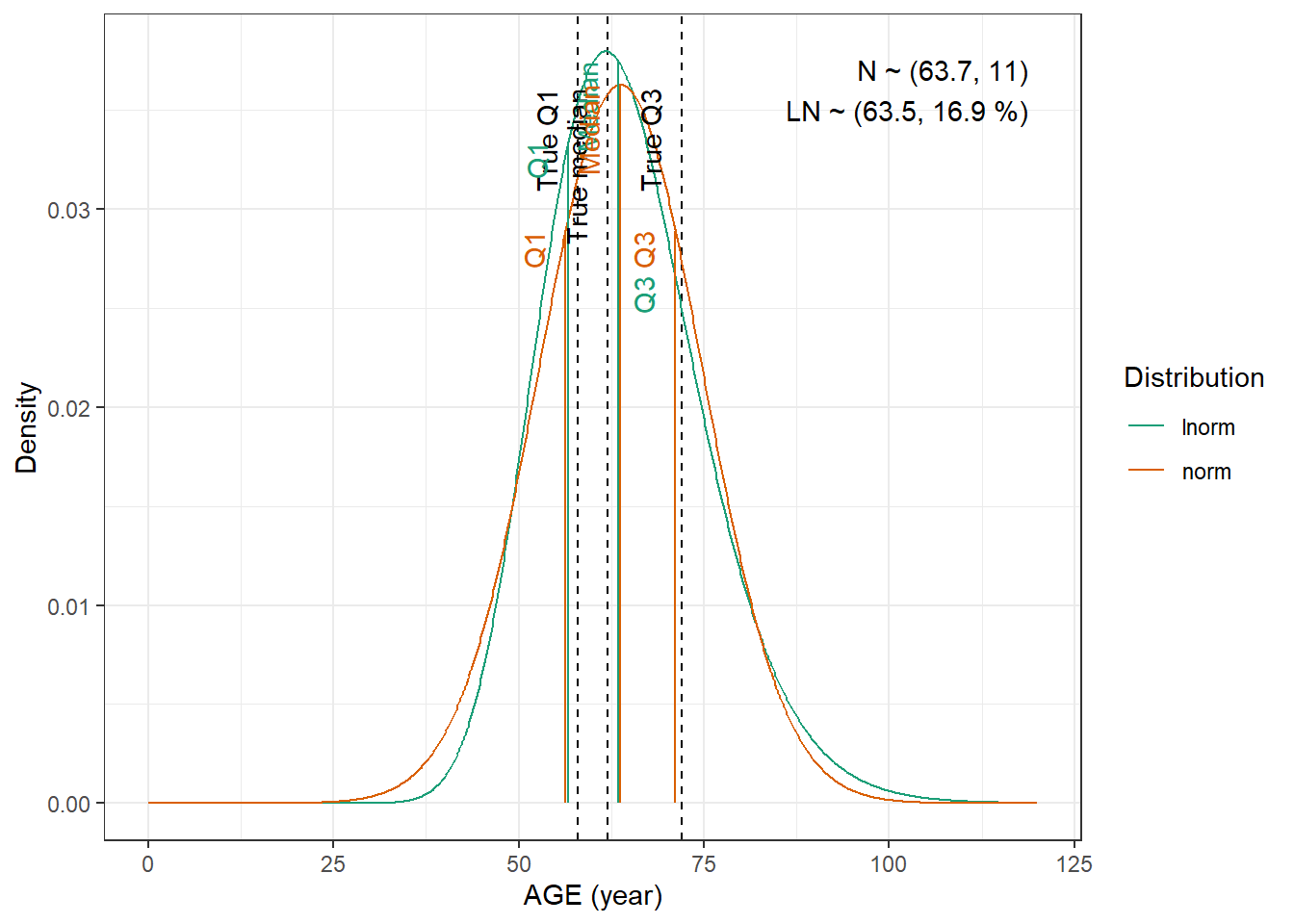
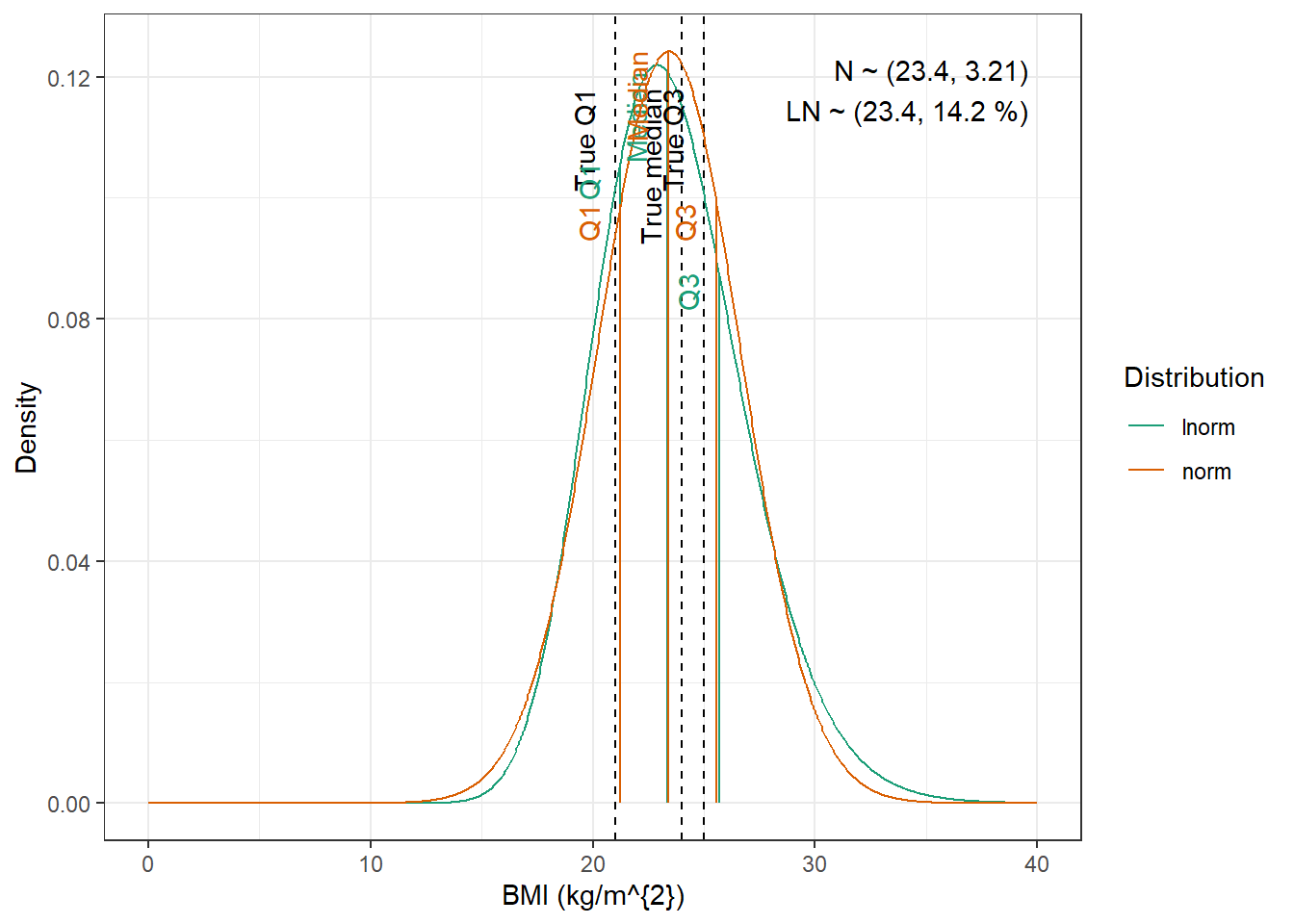
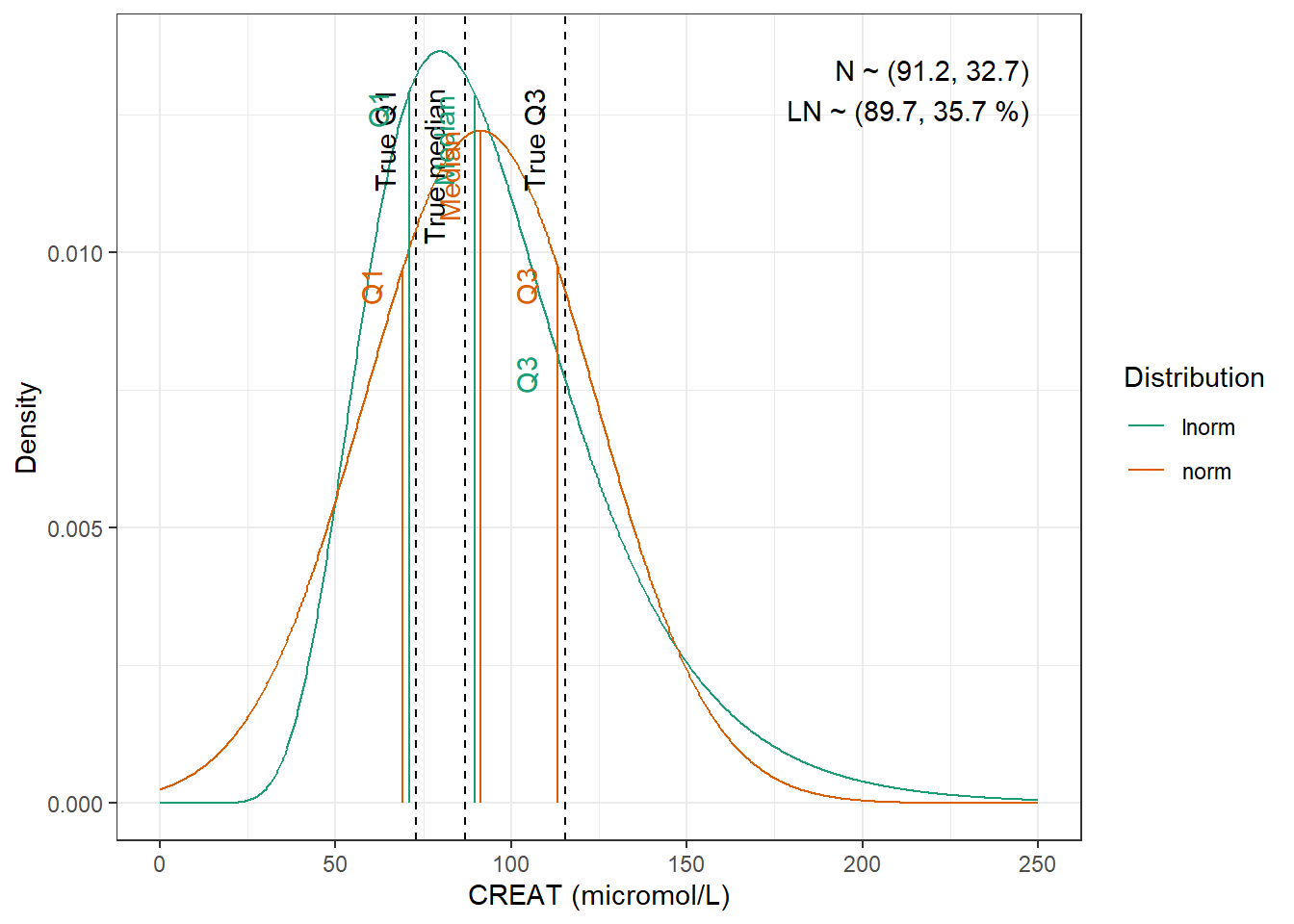
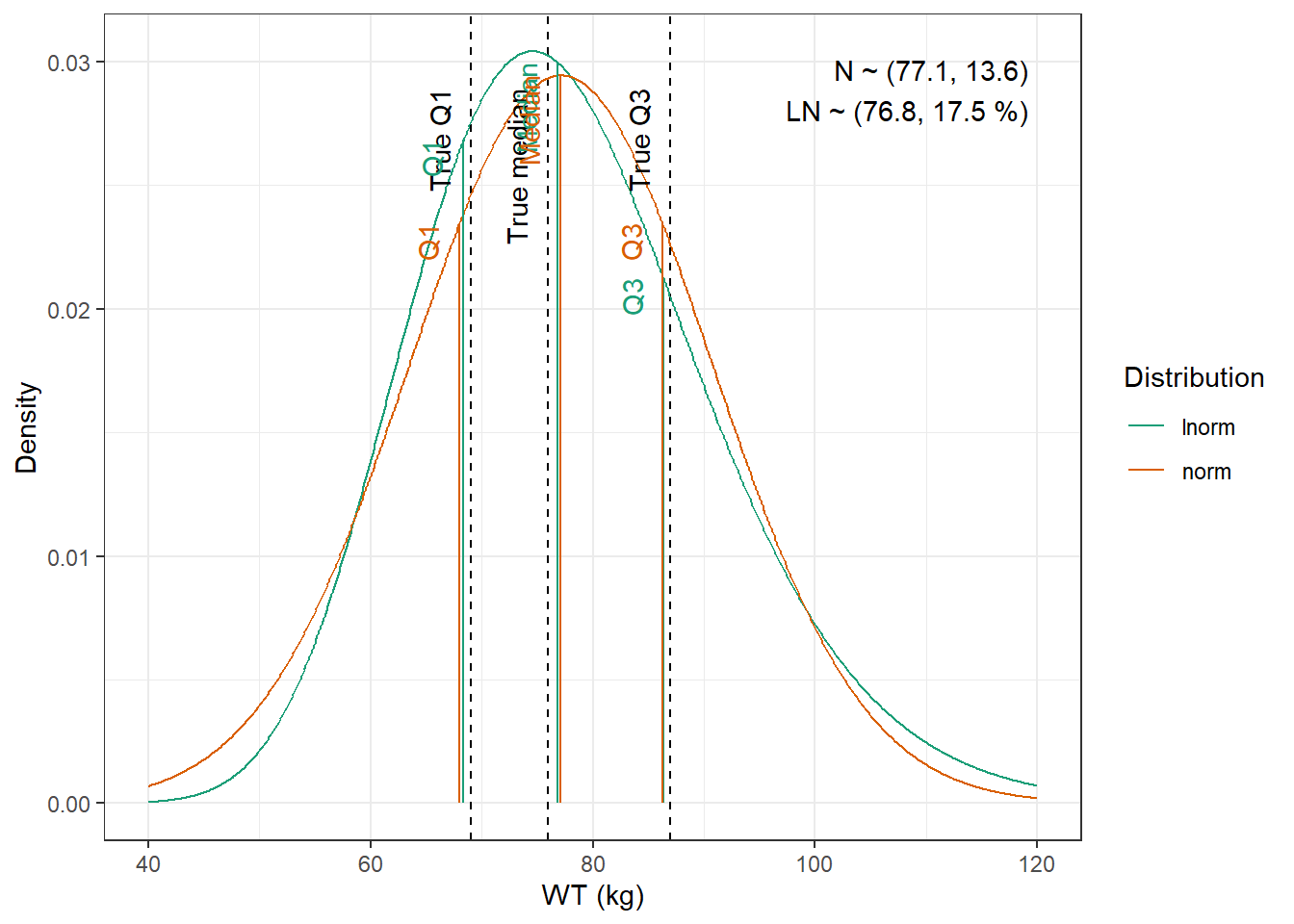
We are going to fit normal and log-normal distributions to the observed quantiles and select the best fitting one
Show the code
compute_cv_from_sd_lnorm <-function(sdlog){#' Compute the geometric coefficient of variation from the standard deviation of a lognormal distribution#'#' @param sdlog numeric. standard deviation of the log transformed variable#' #' @return numeric. geometric coefficient of variationsqrt(exp(sdlog^2)-1)}extract_cov_param <-function(cov_data, cov_name) {#' Get covariate quantiles from covariate characteristics table#'#' @param cov_data tibble containing the covariate information#' @param cov_name character. name of the covariate to select, comes from the Covariate column of cov_data.#' @return list with :#' - p : numeric vector of probabilities#' - q : numeric vector of quantiles#' - cov_name : character string containing the covariate name#' - cov_unit : character string containing the unit of the covariate cov_filtered_df <- cov_data |>filter(Covariate == cov_name) |>pivot_longer(cols =c(Median, Q1, Q3, Min, Max), # if the format of the csv columns ever changes, this will need to changenames_to ="p",values_to ="q" ) |>mutate(p =case_match(p, "Median"~0.5, "Q1"~0.25, "Q3"~0.75, "Min"~0.01, "Max"~0.99)) |># if the format of the csv columns ever changes, the code above will need to changefilter(!is.na(q)) |>group_by(Paper) |>arrange(p, .by_group =TRUE) |>ungroup()list(p = cov_filtered_df$p,q = cov_filtered_df$q,cov_name =unique(cov_filtered_df$Covariate),cov_unit =unique(cov_filtered_df$Unit) )}evaluate_distrib <-function(p, q, cov_name, cov_unit, min_plot, max_plot,tol =0.001) {#' Fit normal and lognormal distribution to observed quantiles#' @param p numeric vector of probabilities#' @param q numeric vector of quantiles#' @param cov_name character string containing the covariate name#' @param cov_unit character string containing the unit of the covariate#' @param min_plot minimal value of the covariate for which the distribution should be plotted#' @param max_plot maximal value of the covariate for which the distribution should be plotted#' @param tol numeric. tolerance value for the fitting algorithm, default is 0.001#' @return list with :#' - plot : ggplot2 showing the fitted distributions and the observed covariate#' - lnorm_par : named numeric vector with the lognormal distribution parameters#' - norm_par : named numeric vector with the normal distribution parameters lnorm_par <-get.lnorm.par(p = p, q = q, plot =FALSE, show.output =FALSE,tol = tol) norm_par <-get.norm.par(p = p, q = q, plot =FALSE, show.output =FALSE,tol=tol)#create a dataset with the true percentiles to be able to show them on the plot true_percentiles <-tibble(p, q) |>mutate(label =case_match(p, 0~"True min",0.25~"True Q1",0.5~"True median",0.75~"True Q3",1~"True max")) #create a dataset with the percentiles of the fitted distributiosn to be able to show them on the plot distrib_percentiles <-tibble(probability = p,lnorm =qlnorm(probability, meanlog = lnorm_par["meanlog"], sdlog = lnorm_par["sdlog"]),norm =qnorm(probability, mean = norm_par["mean"], sd = norm_par["sd"]) ) |>pivot_longer(cols =c(lnorm, norm), names_to ="distrib") |>mutate(density =case_match( distrib,"norm"~dnorm(value, mean = norm_par["mean"], sd = norm_par["sd"]),"lnorm"~dlnorm(value, meanlog = lnorm_par["meanlog"], sdlog = lnorm_par["sdlog"]) )) |>mutate(label =case_match(probability, 0~"Min",0.25~"Q1",0.5~"Median",0.75~"Q3",1~"Max")) #simulate 1000 datapoints from the fitted distributions to show on the plot param_data <-tibble(variable =seq(min_plot, max_plot, length.out =1000),lnorm =dlnorm(variable, meanlog = lnorm_par["meanlog"], sdlog = lnorm_par["sdlog"]),norm =dnorm(variable, mean = norm_par["mean"], sd = norm_par["sd"]) ) |>pivot_longer(cols =c(lnorm, norm), names_to ="distrib") plot <-ggplot(param_data, aes(x = variable, y = value, color = distrib)) +geom_vline(data = true_percentiles, mapping =aes(xintercept = q),lty ="dashed") +geom_line() +geom_segment(data = distrib_percentiles, aes(x = value, y =0, yend = density)) +theme_bw() +scale_color_brewer("Distribution", palette ="Dark2") +ylab("Density") +xlab(paste0(cov_name, " (", cov_unit, ")")) +annotate(geom ="text",label =paste0("N ~ (",signif(norm_par["mean"], 3),", ",signif(norm_par["sd"], 3),")\n","LN ~ (",signif(exp(lnorm_par["meanlog"]), 3),", ",signif(compute_cv_from_sd_lnorm(lnorm_par["sdlog"]), 3) *100," %)" ),x =min(param_data$variable) +0.99*diff(range(param_data$variable)),y =min(param_data$value) +0.99*diff(range(param_data$value)),hjust =1,vjust =1 )+geom_text(data = true_percentiles,mapping =aes(x = q,label = label,color=NULL),show.legend =FALSE,y =min(param_data$value) +0.95*diff(range(param_data$value)),hjust =1,vjust =-1,angle =90 )+geom_text(data = distrib_percentiles,mapping =aes(x = value, y=density,label = label),show.legend =FALSE,hjust =1,vjust =-1,angle =90 )list(plot = plot,lnorm_par = lnorm_par,norm_par = norm_par)}fit_cov_wrapper <-function(cov_data, cov_name, min_plot, max_plot, tol =0.001) {#' Wrapper to get covariate quantiles from covariate characteristics table and fit normal and lognormal distribution#' to observed quantiles #'#' @param cov_data tibble containing the covariate information#' @param cov_name character. name of the covariate to select, comes from the Covariate column of cov_data.#' @param min_plot minimal value of the covariate for which the distribution should be plotted#' @param max_plot maximal value of the covariate for which the distribution should be plotted#' @param tol numeric. tolerance value for the fitting algorithm, default is 0.001#' @return list with :#' - plot : ggplot2 showing the fitted distributions and the observed covariate#' - lnorm_par : named numeric vector with the lognormal distribution parameters#' - norm_par : named numeric vector with the normal distribution parameters cov_df <-extract_cov_param(cov_data, cov_name)evaluate_distrib(p = cov_df$p,q = cov_df$q,min_plot = min_plot,max_plot = max_plot,cov_name = cov_df$cov_name,cov_unit = cov_df$cov_unit,tol = tol )}
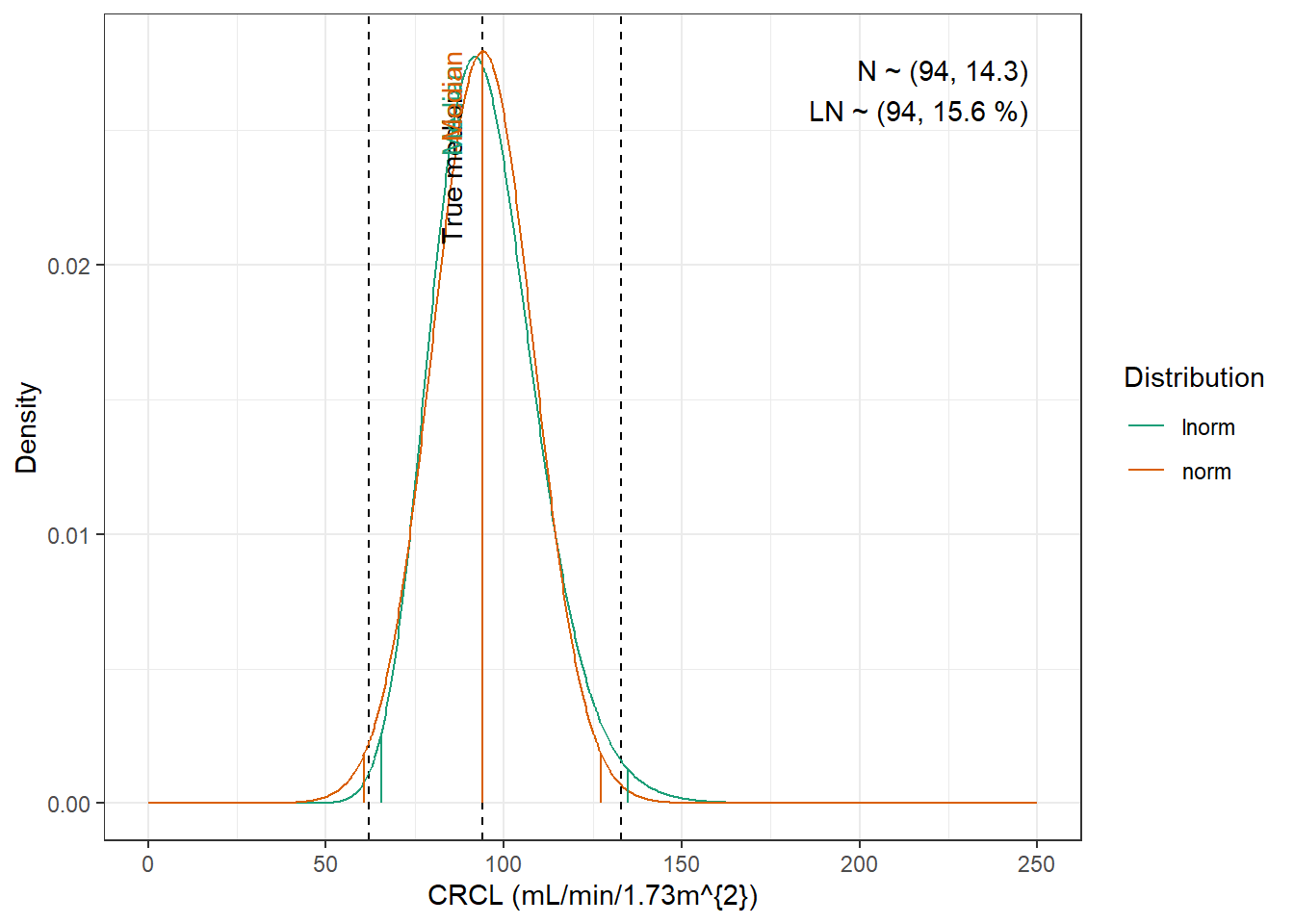
Tolerance was increased to 0.002. No discernible difference in fit. We have to use the log-normal distribution to be able to obtain height.
5.2.2 Simulation of covariates
Covariates will be sampled from the following distributions :
CRCL : Normal distribution with a minimum of 10 mL/min, with mean 105 mL/min and standard deviation 68.5 mL/min
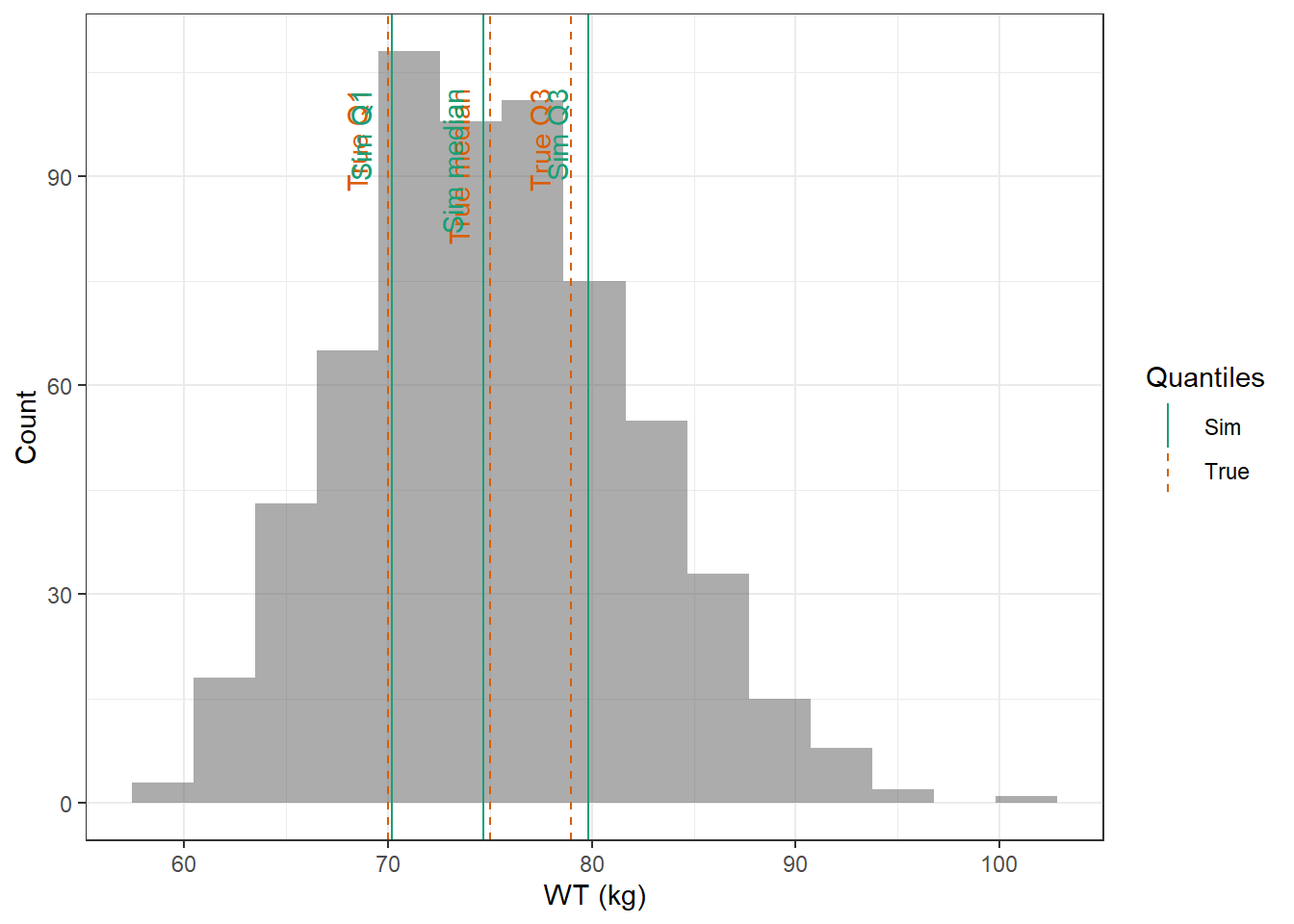
WT : Lognormal distribution with mean 74.6 kg, and coefficient of variation 9.04 %
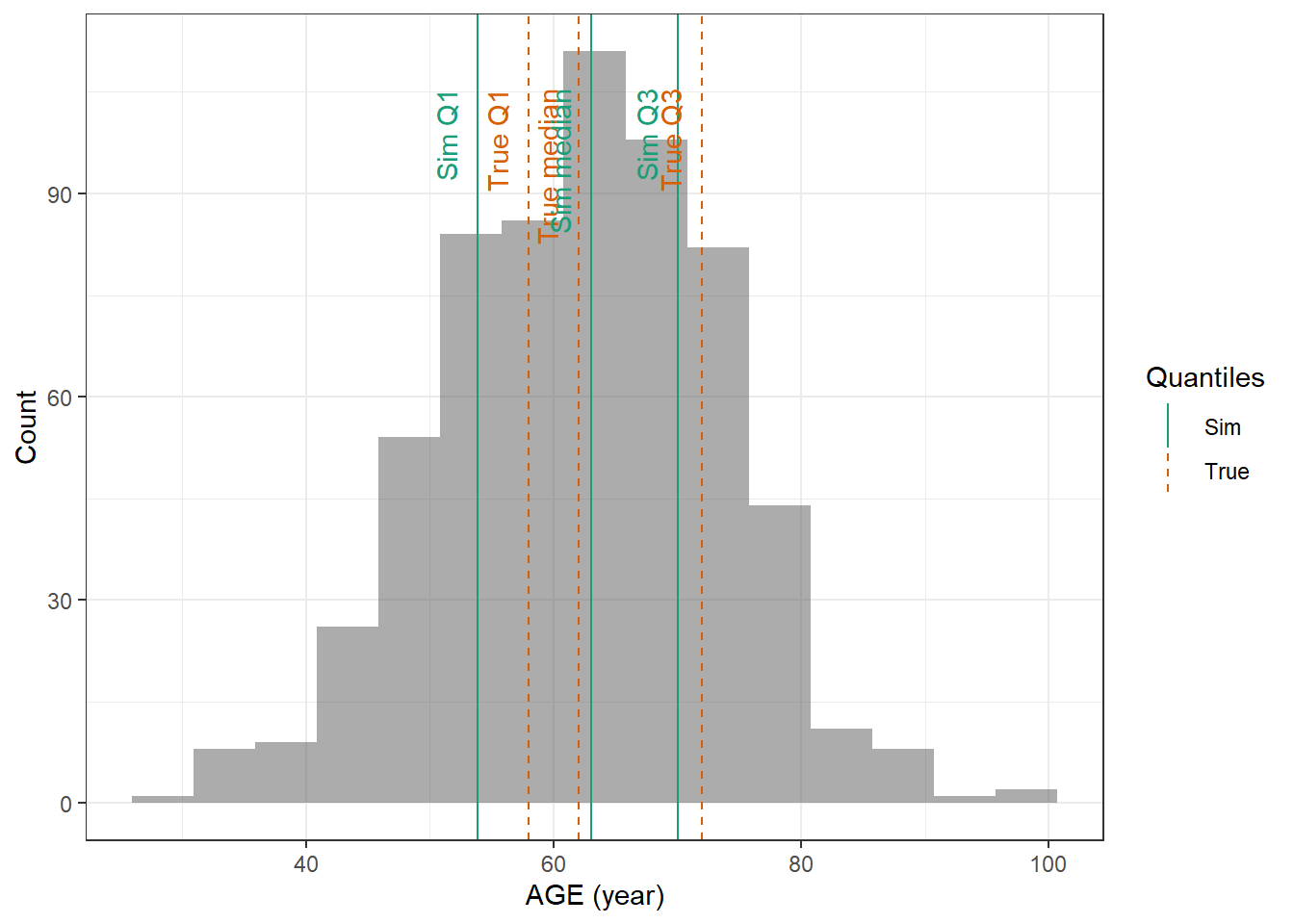
AGE : Normal distribution with mean 63.7 mL/min and standard deviation 11 years and with a minimum of 18 years
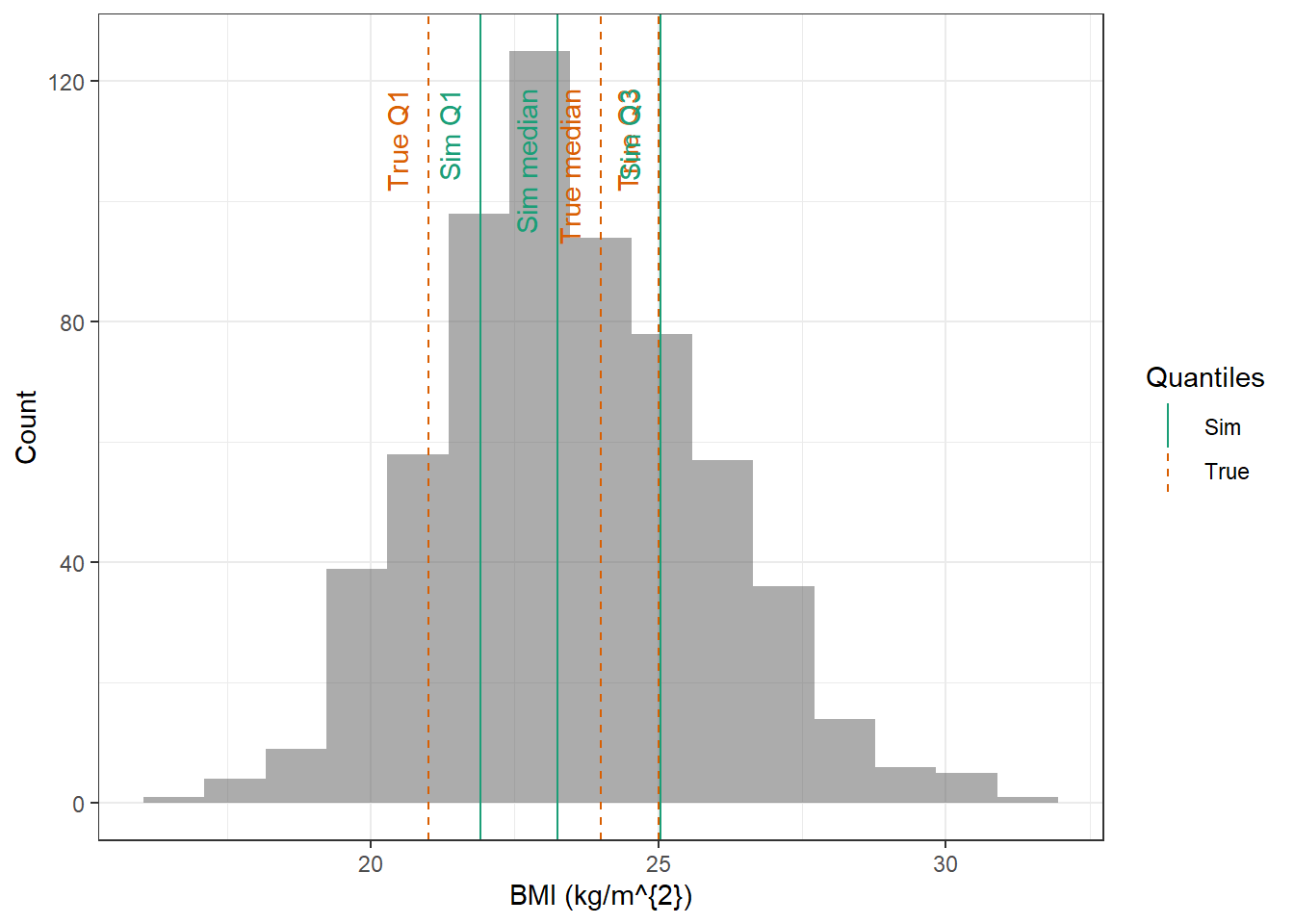
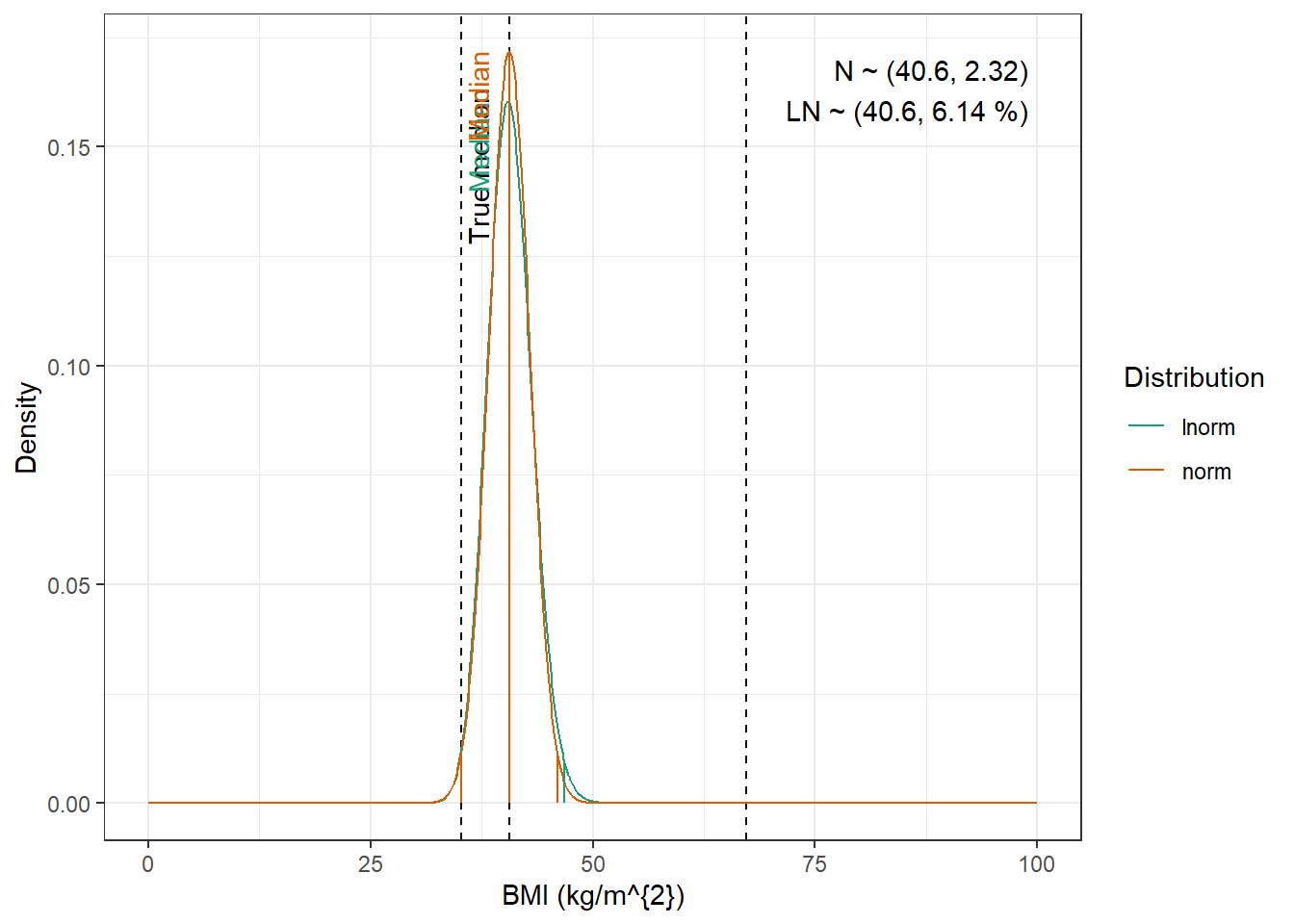
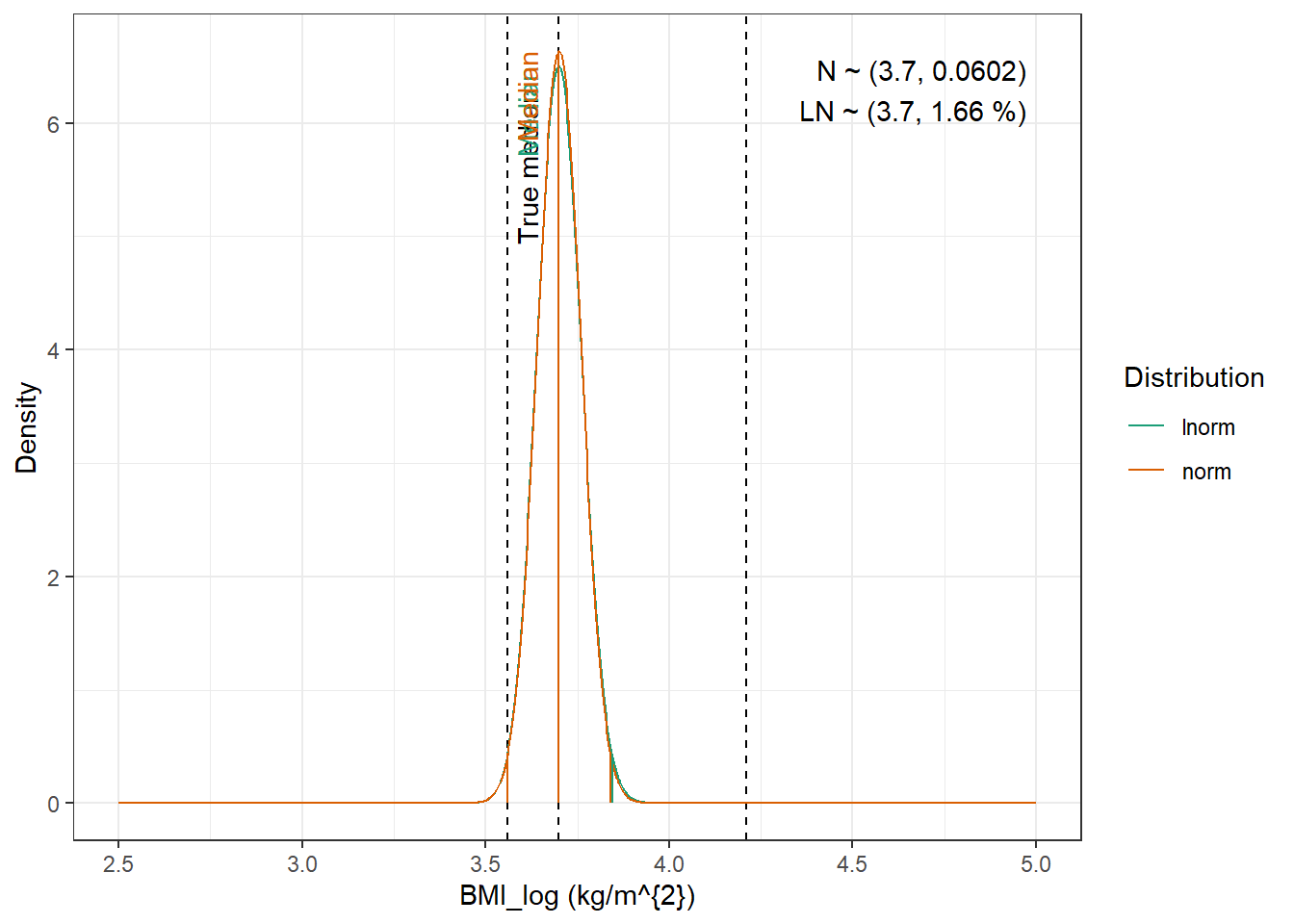
BMI : Log-normal distribution with mean 3.15 mL/min and standard deviation 0.141 kg/m^{2}
Show the code
sim_norm_without_negatives <-function(n,mean,sd){#' Simulate values from normal distribution but resample negative values#'#' @param n numeric. number of samples to simulate#' @param mean numeric. mean of the normal distribution#' @param sd numeric. standard deviation of the normal distribtuion#' @return numeric vector of n values sim_values <-rnorm(n,mean,sd) neg_values <- sim_values[sim_values<=0] pos_values <- sim_values[sim_values>0]while(length(neg_values)>0){ new_values <-rnorm(length(neg_values),mean,sd) sim_values <-c(pos_values,new_values) neg_values <- sim_values[sim_values<=0] pos_values <- sim_values[sim_values>0] } sim_values}# Only for normal distribution when the minimum is 10 ml/min, resample below 10sim_norm_without_dialysis <-function(n,mean,sd){#' Simulate values from normal distribution but resample negative values#'#' @param n numeric. number of samples to simulate#' @param mean numeric. mean of the normal distribution#' @param sd numeric. standard deviation of the normal distribtuion#' @return numeric vector of n values sim_values <-rnorm(n,mean,sd) neg_values <- sim_values[sim_values<=10] pos_values <- sim_values[sim_values>10]while(length(neg_values)>0){ new_values <-rnorm(length(neg_values),mean,sd) sim_values <-c(pos_values,new_values) neg_values <- sim_values[sim_values<=10] pos_values <- sim_values[sim_values>10] } sim_values}# Resimulate subjects younger than 18 years for normally distributed agesim_norm_without_minors <-function(n,mean,sd){#' Simulate values from normal distribution but resample negative values#'#' @param n numeric. number of samples to simulate#' @param mean numeric. mean of the normal distribution#' @param sd numeric. standard deviation of the normal distribtuion#' @return numeric vector of n values sim_values <-rnorm(n,mean,sd) neg_values <- sim_values[sim_values<18] pos_values <- sim_values[sim_values>=18]while(length(neg_values)>0){ new_values <-rnorm(length(neg_values),mean,sd) sim_values <-c(pos_values,new_values) neg_values <- sim_values[sim_values<18] pos_values <- sim_values[sim_values>=18] } sim_values}
The relevant part of the correlation matrix is converted to a covariance matrix by multiplying the already calculated standard deviations of the variables with the diagonal of the correlation matrix. More information can be found at SAS and at stats. A multivariate normal distribution is fitted with resimulation of CRCL below 10 ml/min, AGE below 18 years, and other variables below 0.
The proportion of males is 0.85 in the original article, so the number of males is 531 and the number of females is 94 to add up to 625.
Show the code
mean_WT_log <-as.numeric(carlier_wt$lnorm_par["meanlog"])sd_WT_log <-as.numeric(carlier_wt$lnorm_par["sdlog"])mean_BMI_log <-as.numeric(carlier_bmi$lnorm_par["meanlog"])sd_BMI_log <-as.numeric(carlier_bmi$lnorm_par["sdlog"])r_M <-0.34# Pearson correlation between HT_log and WT_log for malesr_F <-0.36# Pearson correlation for females# sd is different based on sexmean_HT_log = (mean_WT_log - mean_BMI_log) /2sd_HT_M_log = (-r_M * sd_WT_log +sqrt(r_M^2* sd_WT_log^2- sd_WT_log^2+ sd_BMI_log^2))/2# quadratic equation with positive resultsd_HT_F_log = (-r_F * sd_WT_log +sqrt(r_F^2* sd_WT_log^2- sd_WT_log^2+ sd_BMI_log^2))/2# quadratic equation with positivecorrelated_simulation <-function(n, means, cov_matrix) {set.seed(1991) collected <-matrix(NA, 0, length(means))colnames(collected) <-names(means)while (nrow(collected) < n) { batch <- MASS::mvrnorm(n = n, mu = means, Sigma = cov_matrix)colnames(batch) <-names(means) valid <- batch[, "AGE"] >=18& batch[, "CRCL_MDRD"] >=10 batch_valid <- batch[valid, , drop =FALSE] collected <-rbind(collected, batch_valid) } collected[1:n, , drop =FALSE]}means <-c(CRCL_MDRD = carlier_crcl$norm_par["mean"],WT_log = carlier_wt$lnorm_par["meanlog"],AGE = carlier_age$norm_par["mean"],HT_log = mean_HT_log)sds_M <-c(CRCL_MDRD = carlier_crcl$norm_par["sd"],WT_log = carlier_wt$lnorm_par["sdlog"], AGE = carlier_age$norm_par["sd"],HT_log = sd_HT_M_log)sds_F <-c(CRCL_MDRD = carlier_crcl$norm_par["sd"],WT_log = carlier_wt$lnorm_par["sdlog"], AGE = carlier_age$norm_par["sd"],HT_log = sd_HT_F_log)covariates <-c("CRCL_MDRD", "WT_log", "AGE", "HT_log")names(means) <- covariates# Correlation and Covariance Matrixcor_carlier_M <- cor_matrix_Carlier_M[covariates, covariates]cov_matrix_M <-diag(sds_M) %*% cor_carlier_M %*%diag(sds_M)eigen(cov_matrix_M)$values
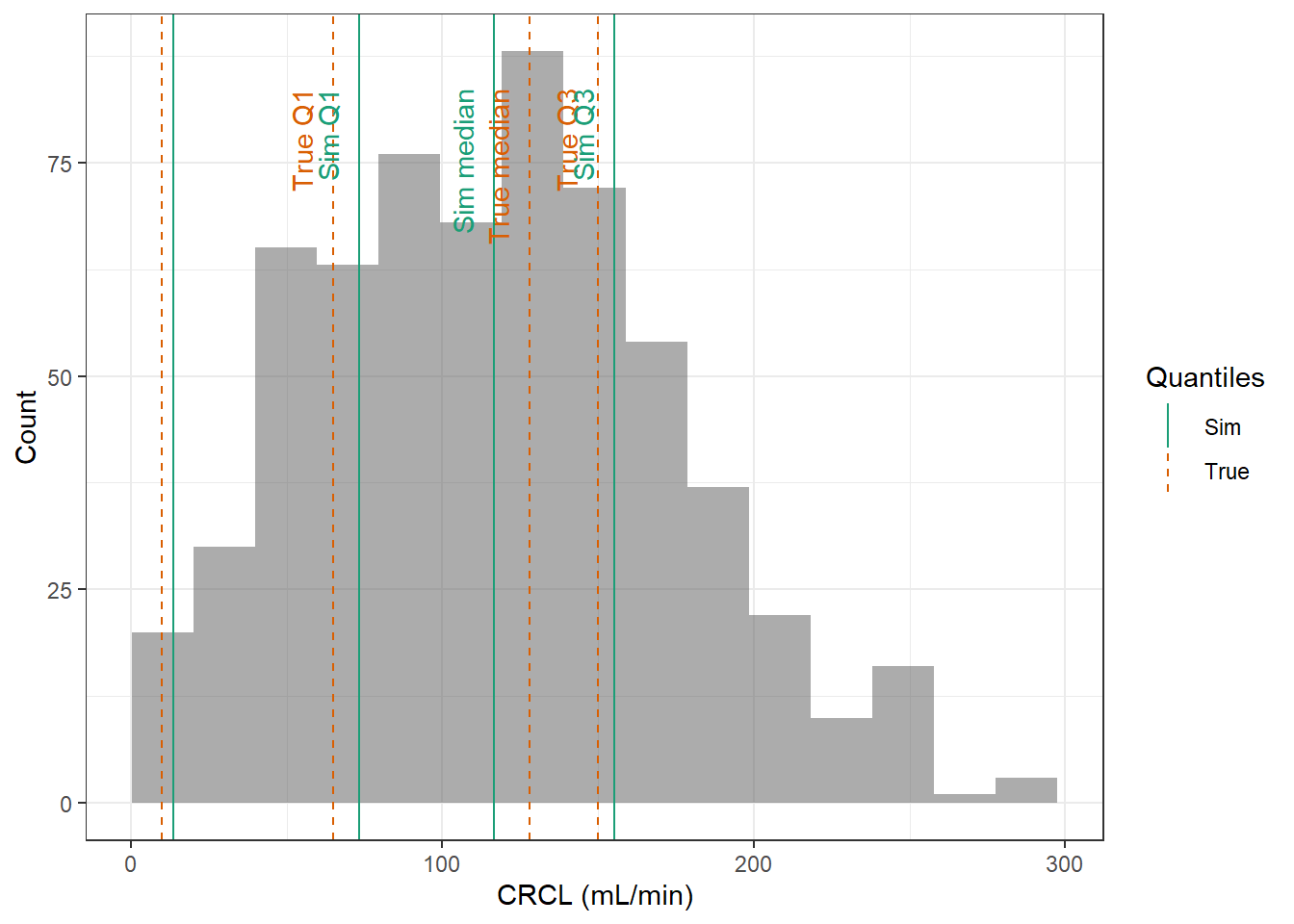
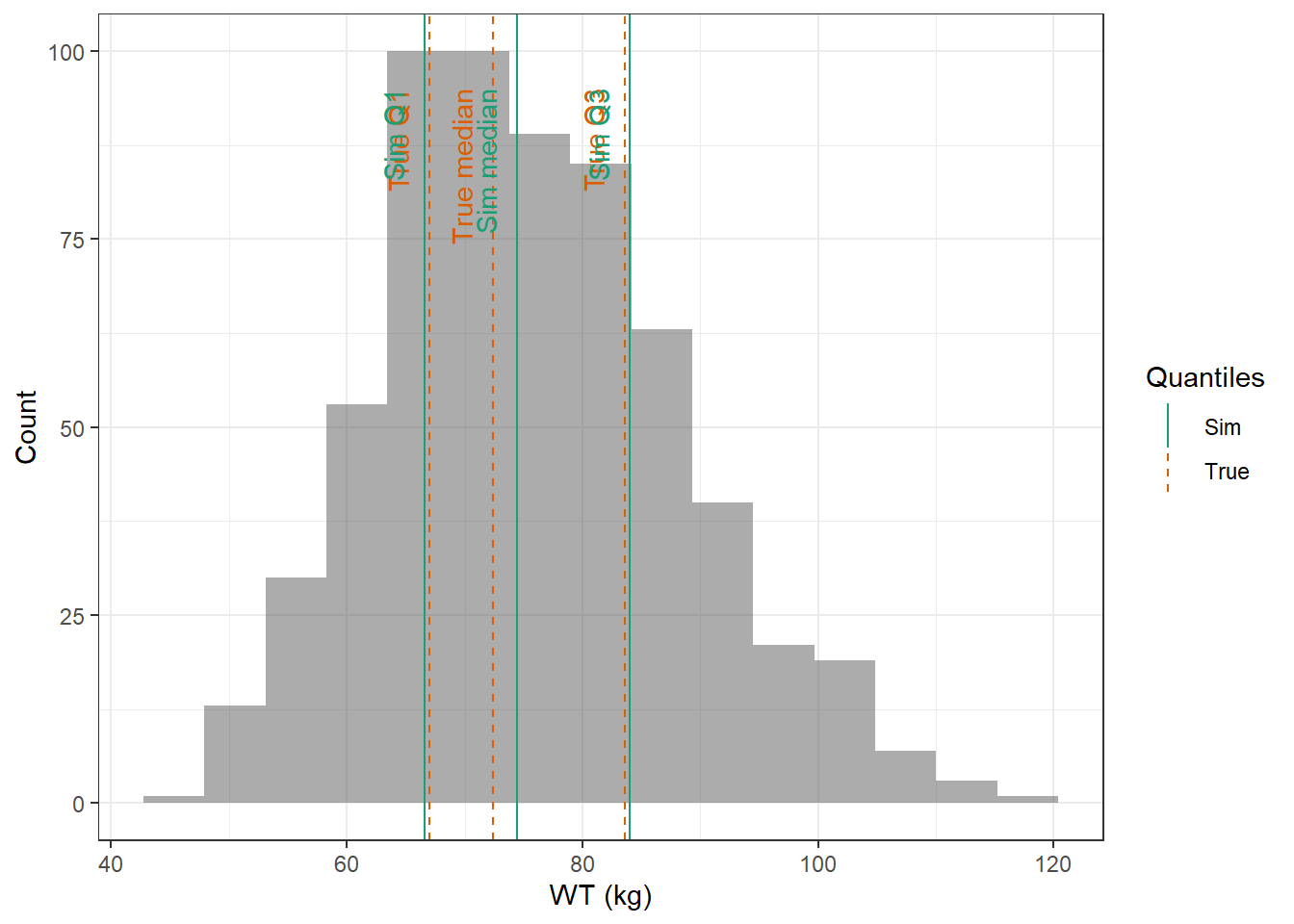
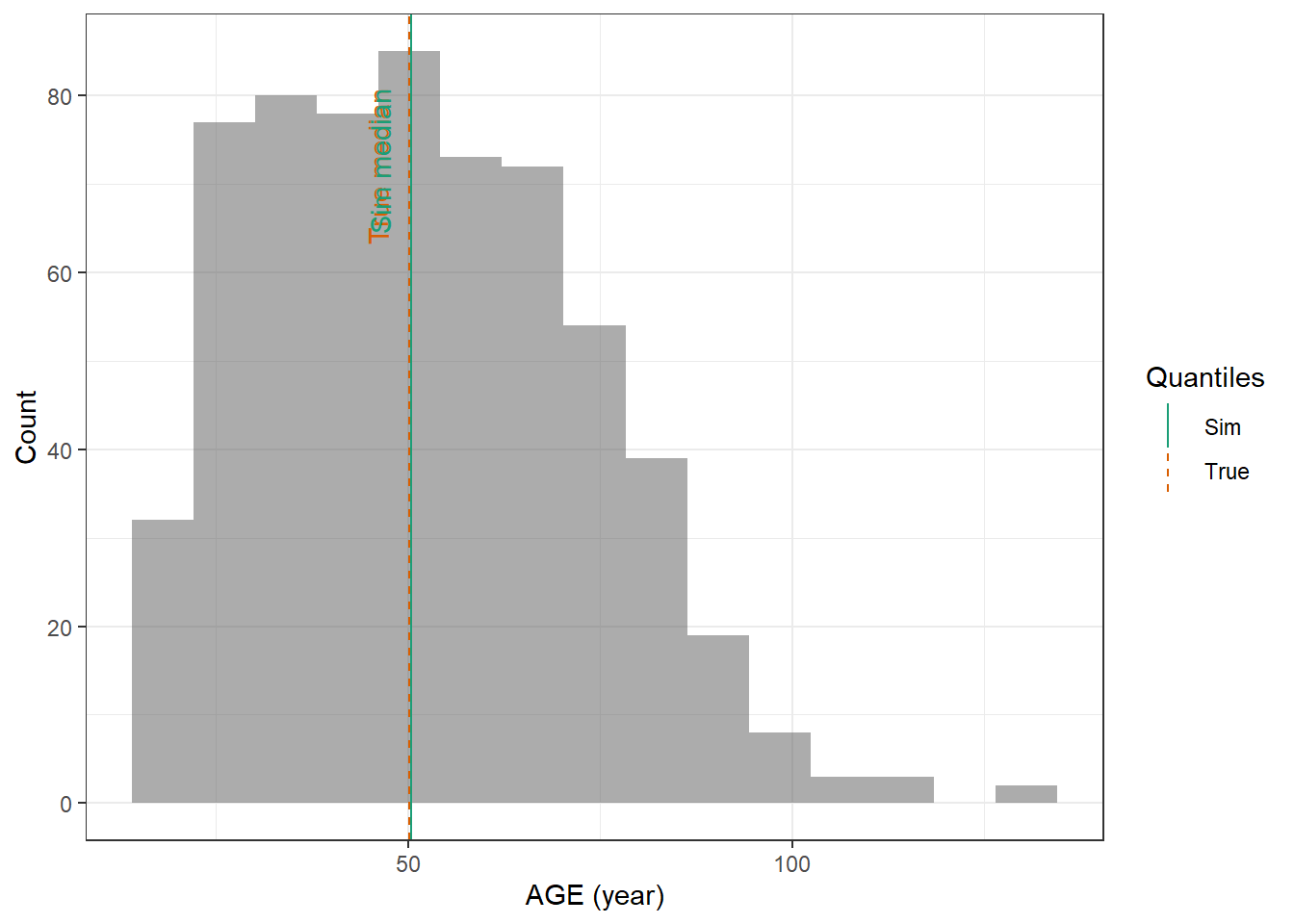
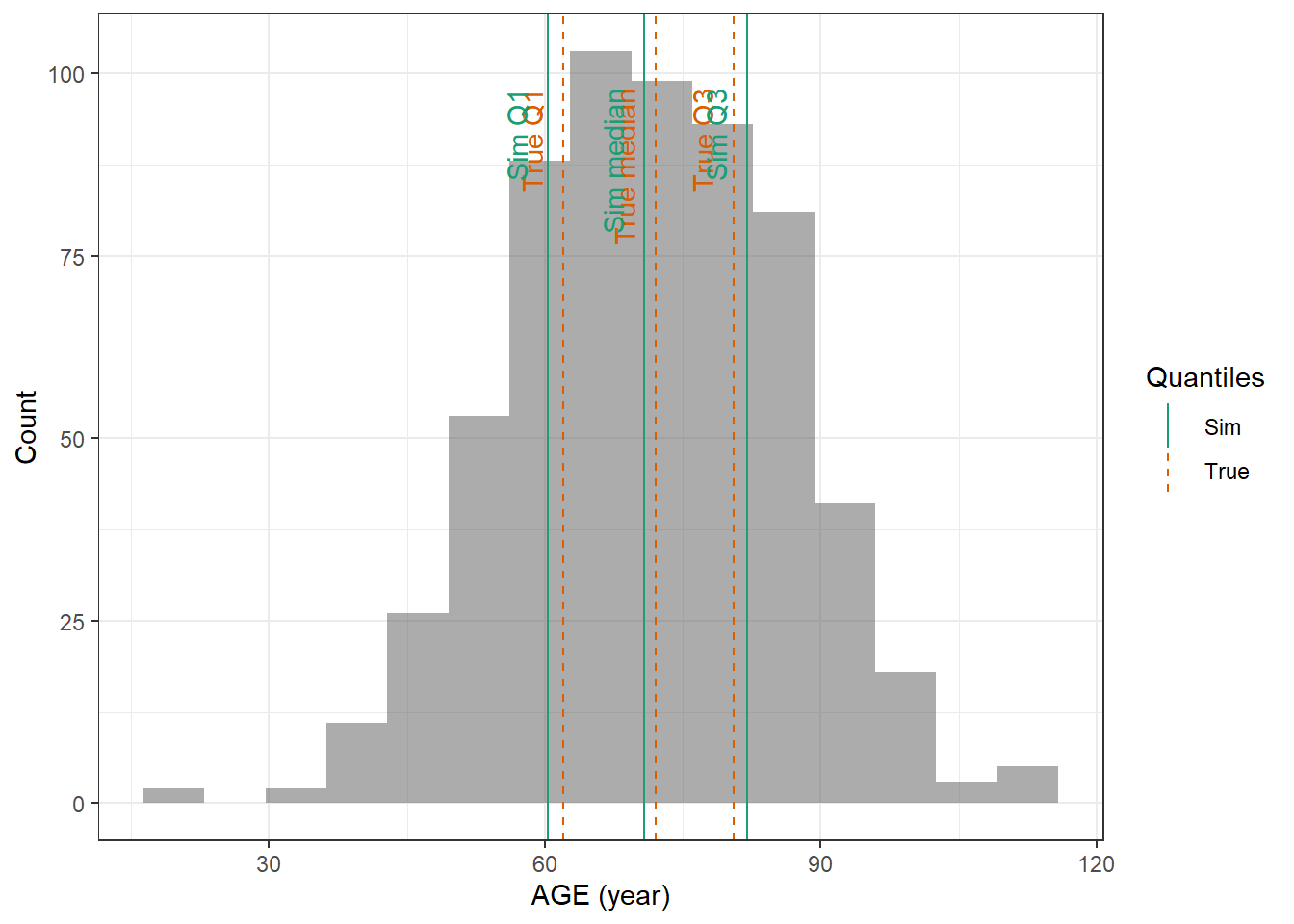
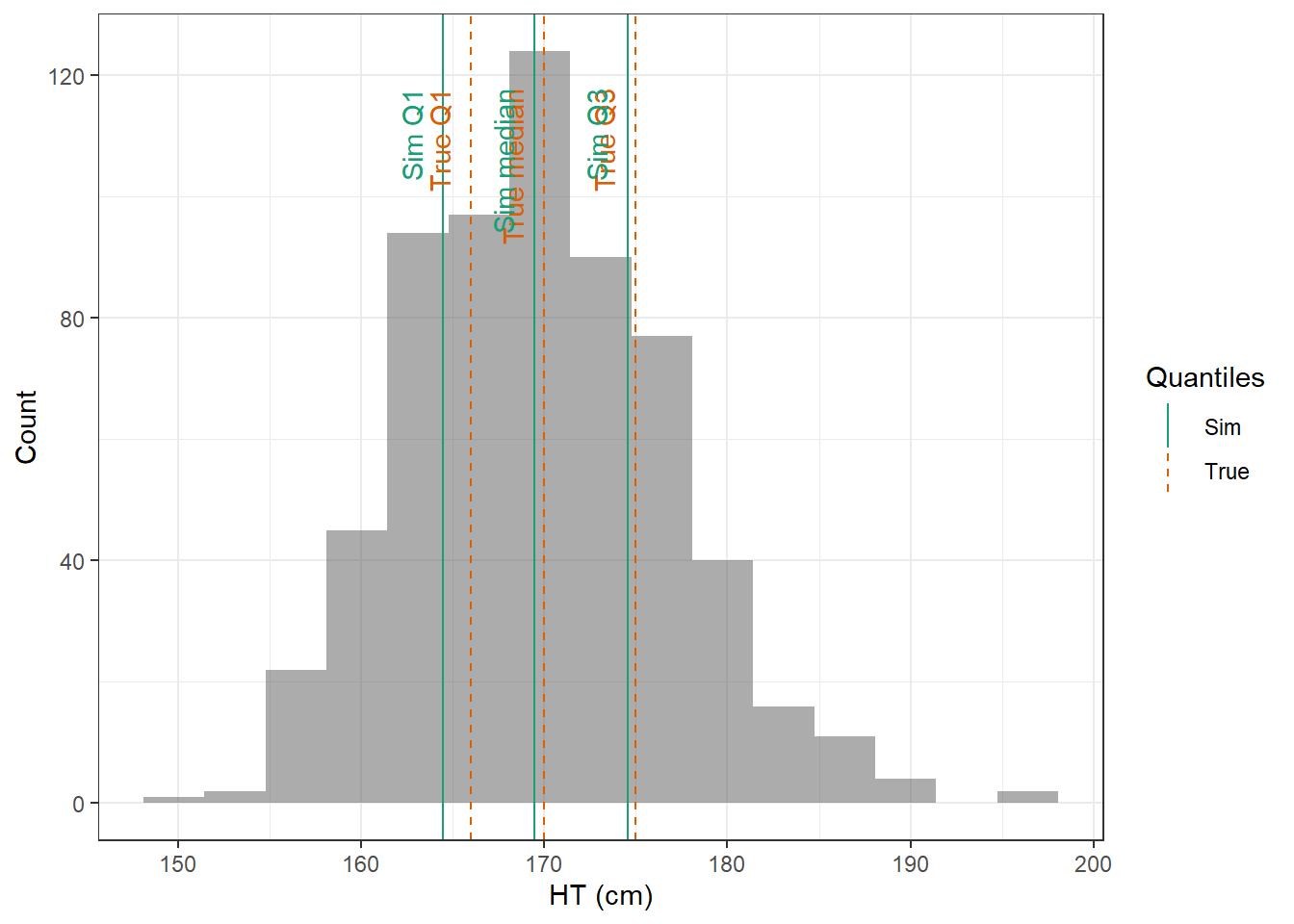
evaluate_cov_sim <-function(p, q, cov_name, cov_unit, cov_sim) {#' Plot simulated covariate distribution versus observed quantiles from the paper#' @param p numeric vector of probabilities#' @param q numeric vector of quantiles#' @param cov_name character string containing the covariate name#' @param cov_unit character string containing the unit of the covariate#' @param cov_sim tibble containing the simulated values for the covariate#' @return ggplot2 showing the distributions of the simulated covariate and the observed covariate quantiles#create a dataset with the true percentiles to be able to show them on the plot true_percentiles <-tibble(p, q) |>mutate(label =case_match(p, 0~"True min",0.25~"True Q1",0.5~"True median",0.75~"True Q3",1~"True max")) #create a dataset with the percentiles of the fitted distributions to be able to show them on the plot sim_percentiles <-tibble(probability = p,q =quantile(pull(cov_sim,cov_name),p) ) |>mutate(label =case_match(probability, 0~"Sim min",0.25~"Sim Q1",0.5~"Sim median",0.75~"Sim Q3",1~"Sim max"))# create an initial histogram in order to be able to extract statistics of the binned covariatehist_ini <-ggplot(cov_sim, aes(x = .data[[cov_name]])) +geom_histogram(bins=15)hist_data <-layer_data(hist_ini)plot <-ggplot(hist_data) +geom_rect(aes(xmin=xmin,xmax=xmax, ymin=0, ymax=count),alpha =0.5) +geom_vline(data = true_percentiles,mapping =aes(xintercept = q,color ="True"),lty ="dashed") +geom_vline(data = sim_percentiles,mapping =aes(xintercept = q,color ="Sim"),lty ="solid") +theme_bw() +ylab("Count") +xlab(paste0(cov_name, " (", cov_unit, ")")) +geom_text(data = true_percentiles,mapping =aes(x = q, label = label, color ="True"),show.legend =FALSE,y =0.95*max(hist_data$ymax),hjust =1,vjust =-1,angle =90 ) +geom_text(data = sim_percentiles,mapping =aes(x = q, label = label, color ="Sim"),show.legend =FALSE,y =0.95*max(hist_data$ymax),hjust =1,vjust =-1,angle =90 ) +scale_color_brewer(name ="Quantiles",palette ="Dark2") plot}plot_sim_cov_wrapper <-function(cov_data,cov_name,cov_sim){ cov_df <-extract_cov_param(cov_data, cov_name)evaluate_cov_sim(cov_df$p,cov_df$q,cov_df$cov_name,cov_df$cov_unit, cov_sim)}
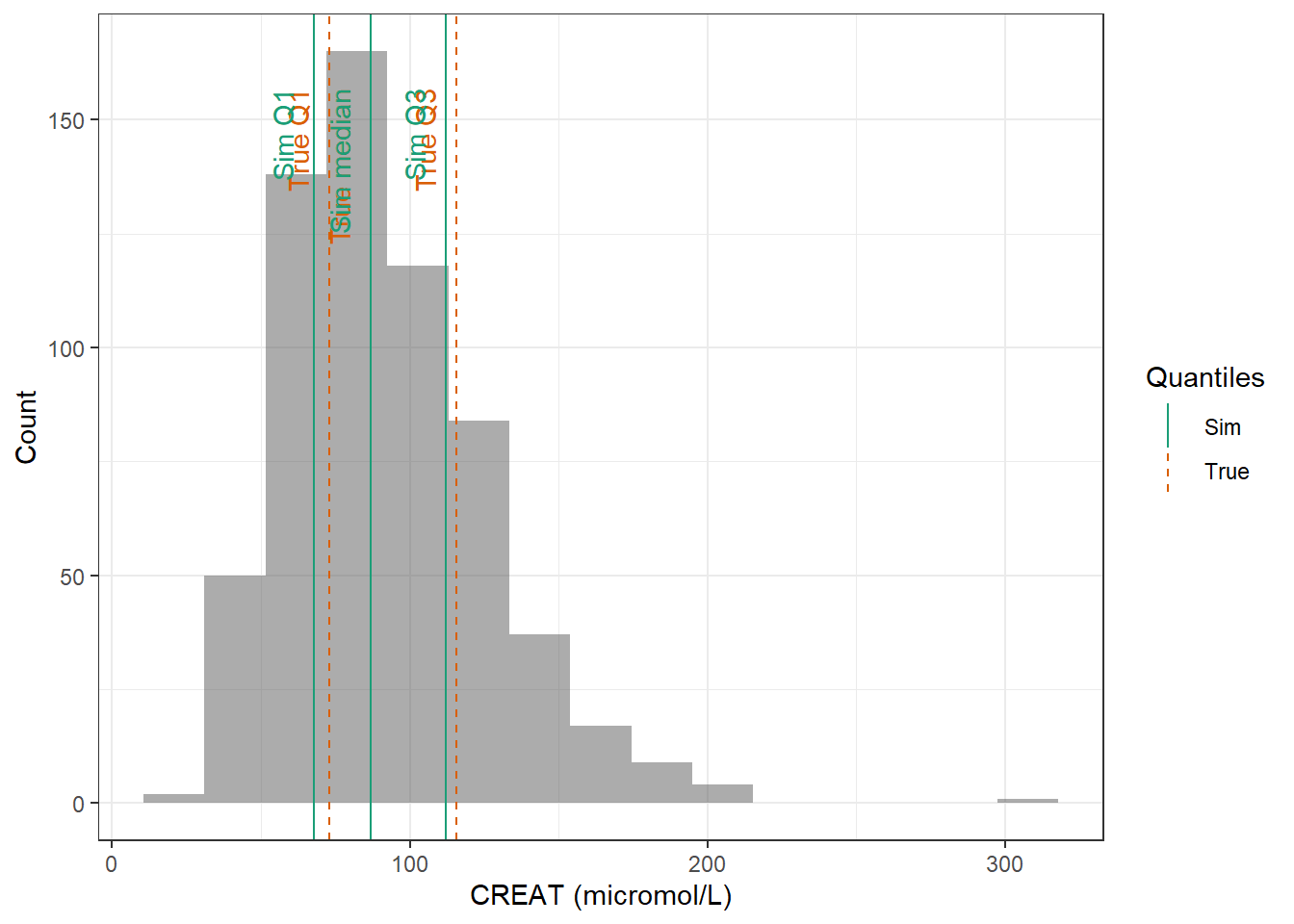
Then, based on BMI and WT, height (HT) is calculated to be able to calculate the body surface area (BSA). CRCL was calculated using the measured urinary equation, and as we have know information about the urinary volume or urinary creatinine concentration, we cannot reconvert CRCL to CREAT based on this equation. The most recommended equation is CKD-EPI, however as different exponents are used based on the value of CREAT, it can’t be used for reconversion of CRCL to CREAT. Thus, the second best equation, MDRD is used.
Show the code
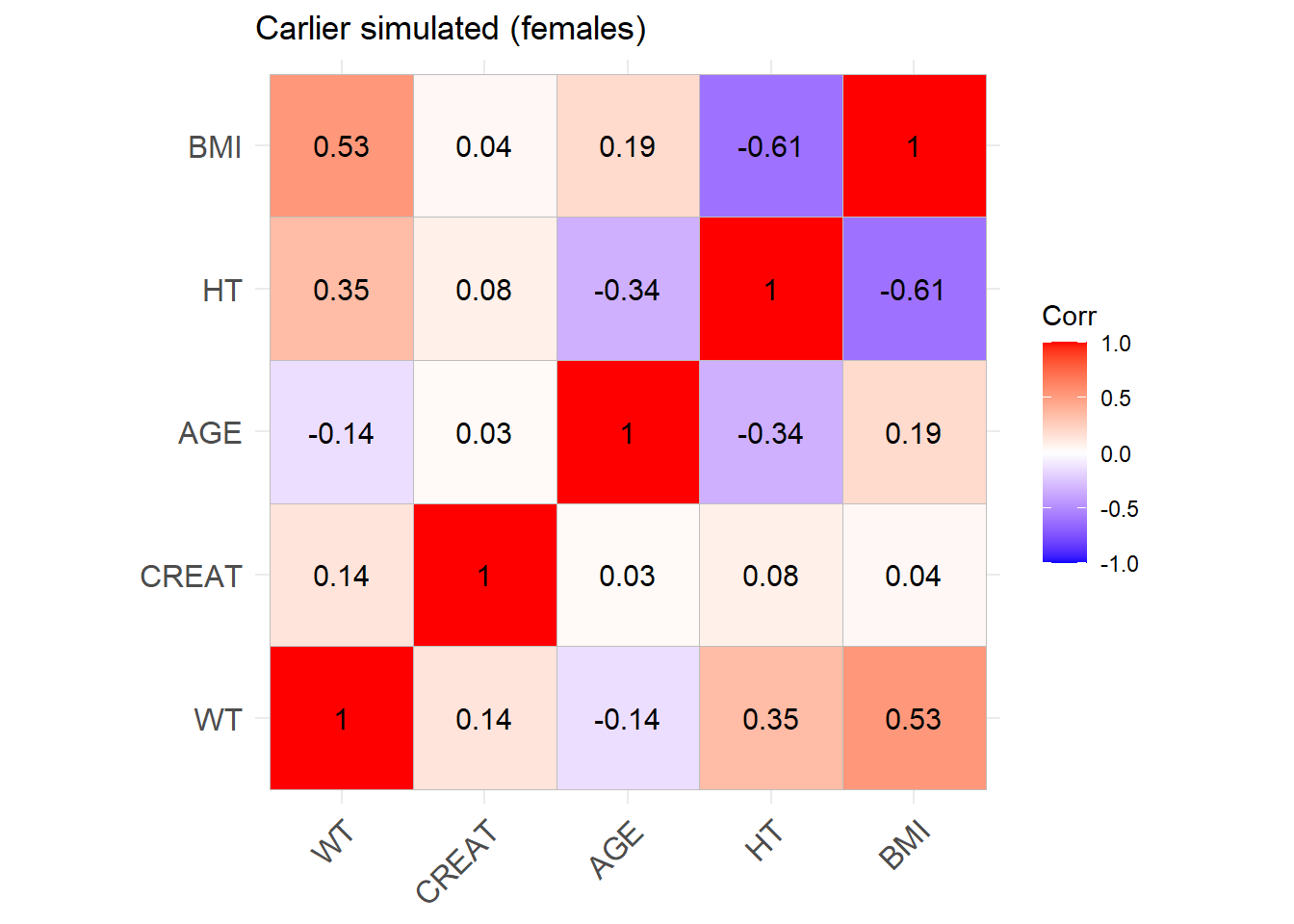
reconvert_MDRD <-function(AGE, CRCL, SEX) {# Mutliply by 0.742 for females sex_factor <-ifelse(SEX ==0, 1, 0.742)# Calculate DFG CREAT <- (CRCL / (175* (AGE^(-0.203)) * sex_factor))^(-1/1.154)return(CREAT)}sim_cov_carlier <- sim_cov_carlier %>%mutate(BSA = (WT^0.425* (HT^0.725) *0.007184), # Calculate body surface area based on Dubois&Dubois formulaCRCL = CRCL * (1.73/BSA) # convert mL/min to mL/min/1.73 m2 )sim_cov_carlier$CREAT <-mapply(reconvert_MDRD, sim_cov_carlier$AGE, sim_cov_carlier$CRCL, sim_cov_carlier$SEX)sim_cov_carlier <- sim_cov_carlier %>% dplyr::select(Paper, ID_within_paper, ICU, BURN, OBESE, CREAT, WT, BSA, BMI, AGE, SEX, HT)# Calculate the simulated correlation matrices separately for the two sexes to compare with the originalsim_cov_carlier_M <- sim_cov_carlier %>%filter(SEX ==0)sim_cov_carlier_F <- sim_cov_carlier %>%filter(SEX ==1)cor_sim_M <-cor(sim_cov_carlier_M %>% dplyr::select(WT, CREAT, AGE, HT, BMI), use ="complete.obs")cor_sim_F <-cor(sim_cov_carlier_F %>% dplyr::select(WT, CREAT, AGE, HT, BMI), use ="complete.obs")ggcorrplot(cor_matrix_Carlier_F, lab =TRUE, title ="Carlier original (females)")
Show the code
Carlier_F <-ggcorrplot(cor_sim_F, lab =TRUE, title ="Carlier simulated (females)")Carlier_F
Show the code
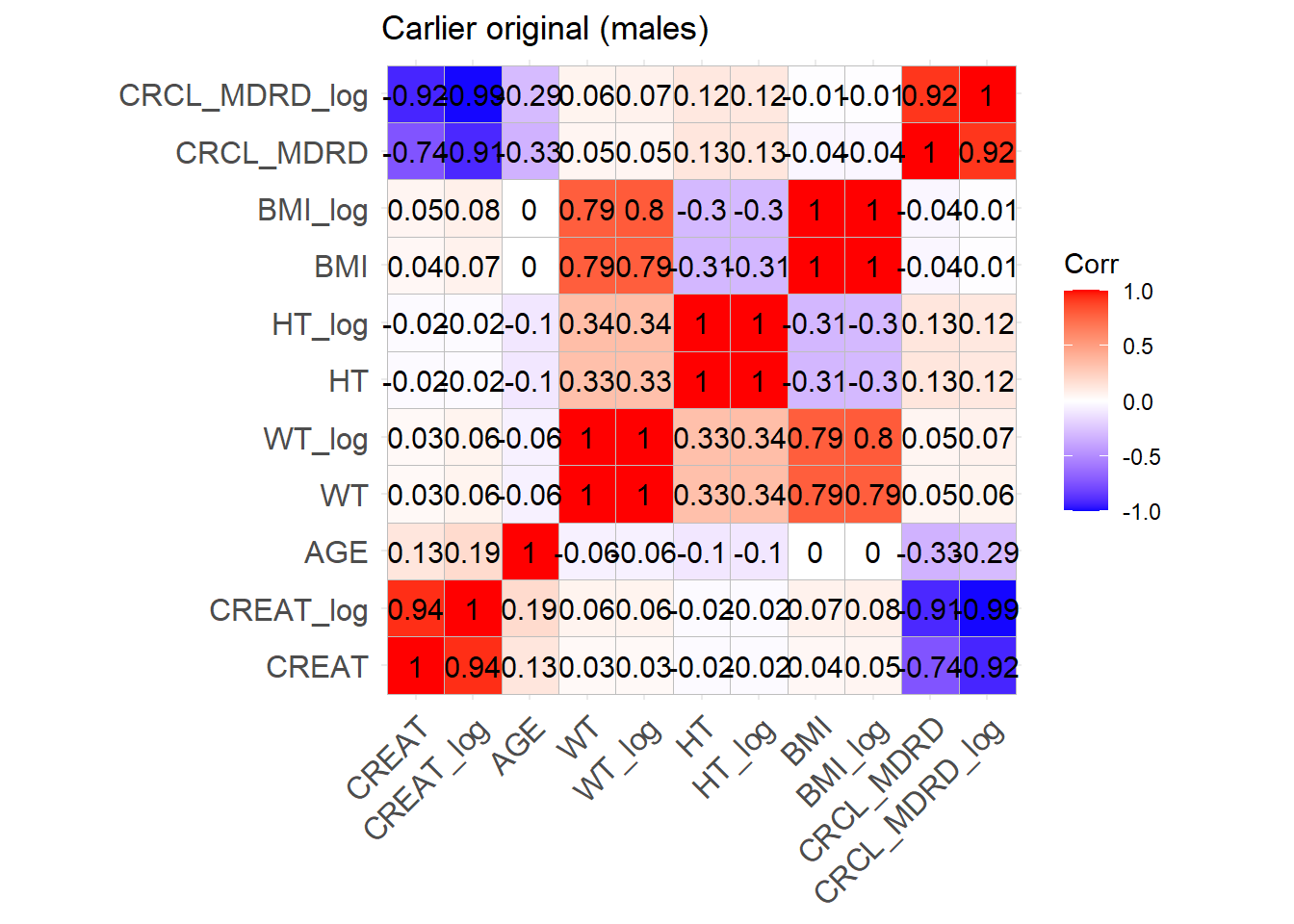
ggcorrplot(cor_matrix_Carlier_M, lab =TRUE, title ="Carlier original (males)")
Show the code
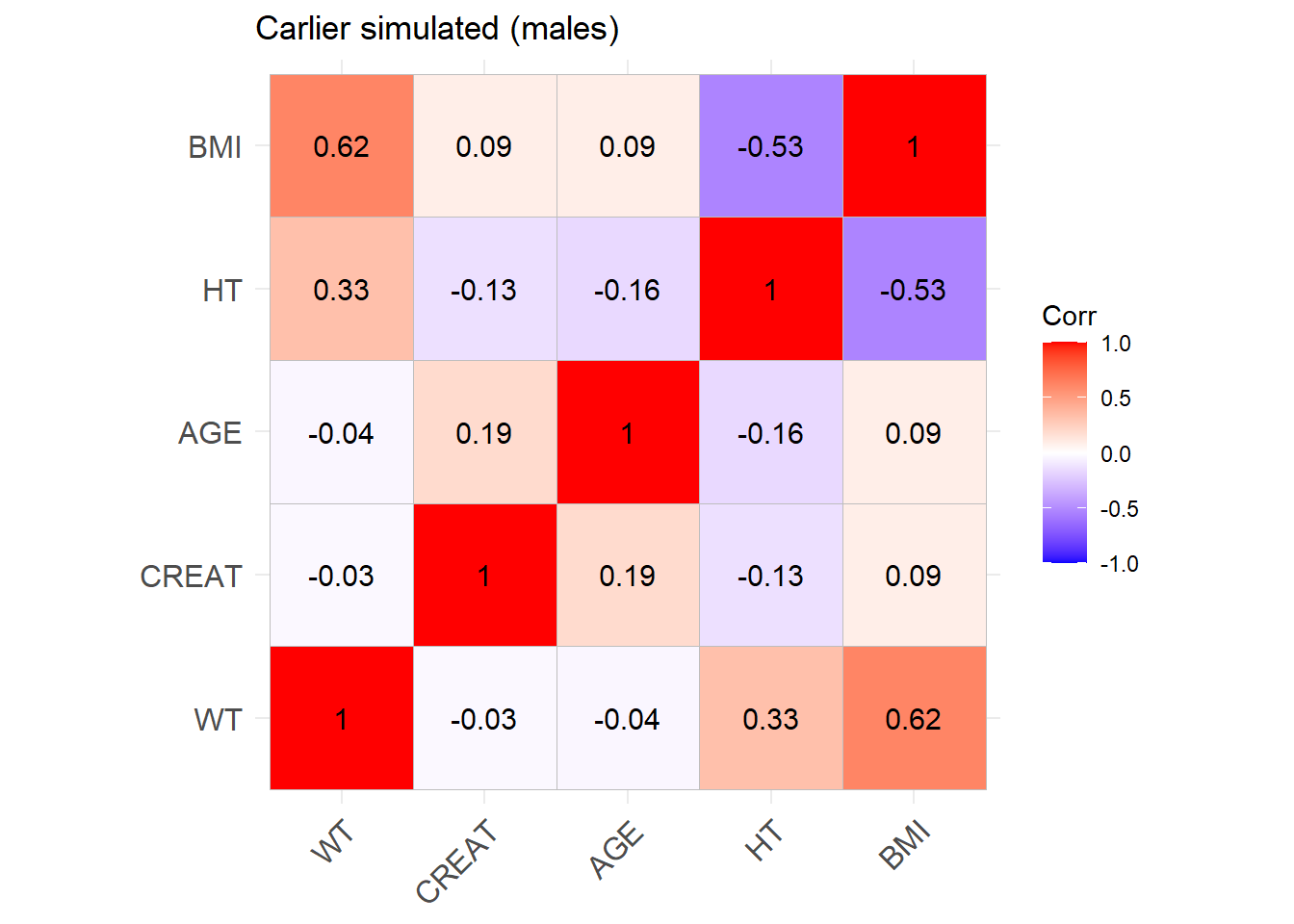
Carlier_M <-ggcorrplot(cor_sim_M, lab =TRUE, title ="Carlier simulated (males)")Carlier_M
This study includes only 21 patients, thus deriving distributions from the reported covariates values might be difficult
5.4.1 Covariate distribution
All patients are ICU patients with burns who are assumed to be non obese. Creatinine clearance is calculated based on the Cockcroft & Gault equation, whose output is in mL/min, so there is no need to calculate BSA. Thus for all patients ICU = 1, BURN = 1 and OBESE=0.
It is not mentioned in the article if certain patients are on renal replacement therapy, therefore we assume that they are not, and set the minimum value of creatinine clearance to 10 mL/min. CRCL was estimated using the Cockroft and Gault equation.
For AGE, not the median and IQR is given but the mean (50.1) and standard deviation (24.3). As we cannot compare the simulated distribution to the true one, so we suppose that the distribution follows a normal distribution.
The proportion of males in the original article is 0.762.
Neither BMI nor HT or BSA are provided in the article, thus the height is simulated based on the height obtained from the MIMIC clinical dataset (normal distribution with mean of 169 and sd of 10.3).
For WT, AGE and CRCL here are the data from the paper :
Then, based on the BMI and WT, the height (HT) is calculated to be able to calculate the body surface area (BSA). CRCL is reconverted to serum creatinine (CREAT) based on the Cockroft and Gault equation.
Show the code
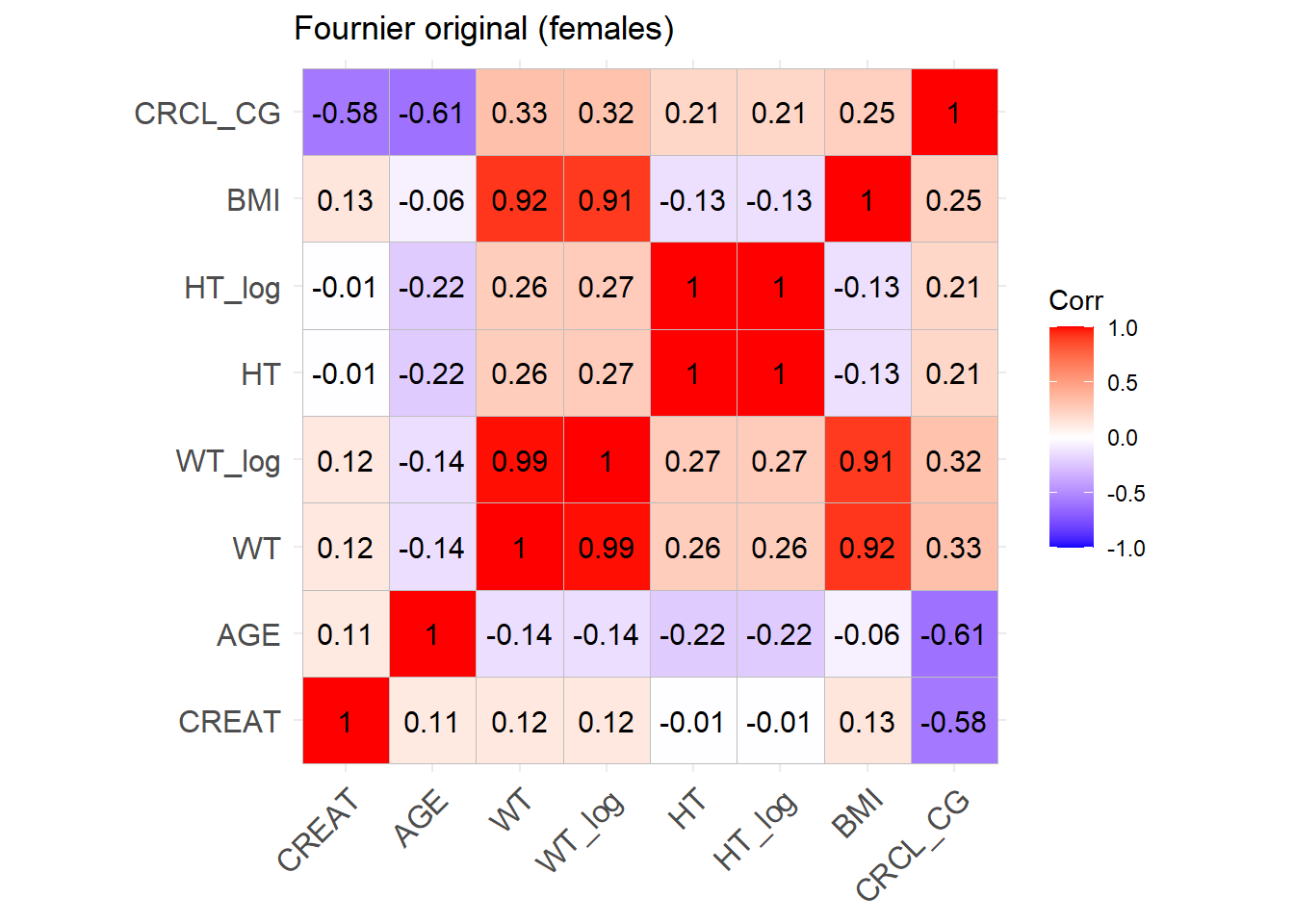
reconvert_CG <-function(AGE, CRCL, SEX, WT) {# Mutliply by 0.85 for females sex_factor <-ifelse(SEX ==0, 1, 0.85)# Calculate DFG CREAT = ((140- AGE) * WT * sex_factor) / (CRCL *72)return(CREAT)}sim_cov_fournier$CREAT <-mapply(reconvert_CG, sim_cov_fournier$AGE, sim_cov_fournier$CRCL, sim_cov_fournier$SEX, sim_cov_fournier$WT)sim_cov_fournier <- sim_cov_fournier %>%mutate(BSA = (WT^0.425* (HT^0.725) *0.007184),BMI = WT / (HT/100)^2,OBESE =ifelse(BMI >30, 1, 0) ) %>% dplyr::select(Paper, ID_within_paper, ICU, BURN, OBESE, CREAT, WT, BSA, BMI, AGE, SEX, HT)# Calculate the simulated correlation matrices separately for the two sexes to compare with the originalsim_cov_fournier_M <- sim_cov_fournier %>%filter(SEX ==0)sim_cov_fournier_F <- sim_cov_fournier %>%filter(SEX ==1)cor_sim_M <-cor(sim_cov_fournier_M %>% dplyr::select(WT, CREAT, AGE, HT, BMI), use ="complete.obs")cor_sim_F <-cor(sim_cov_fournier_F %>% dplyr::select(WT, CREAT, AGE, HT, BMI), use ="complete.obs")ggcorrplot(cor_matrix_Fournier_F, lab =TRUE, title ="Fournier original (females)")
Show the code
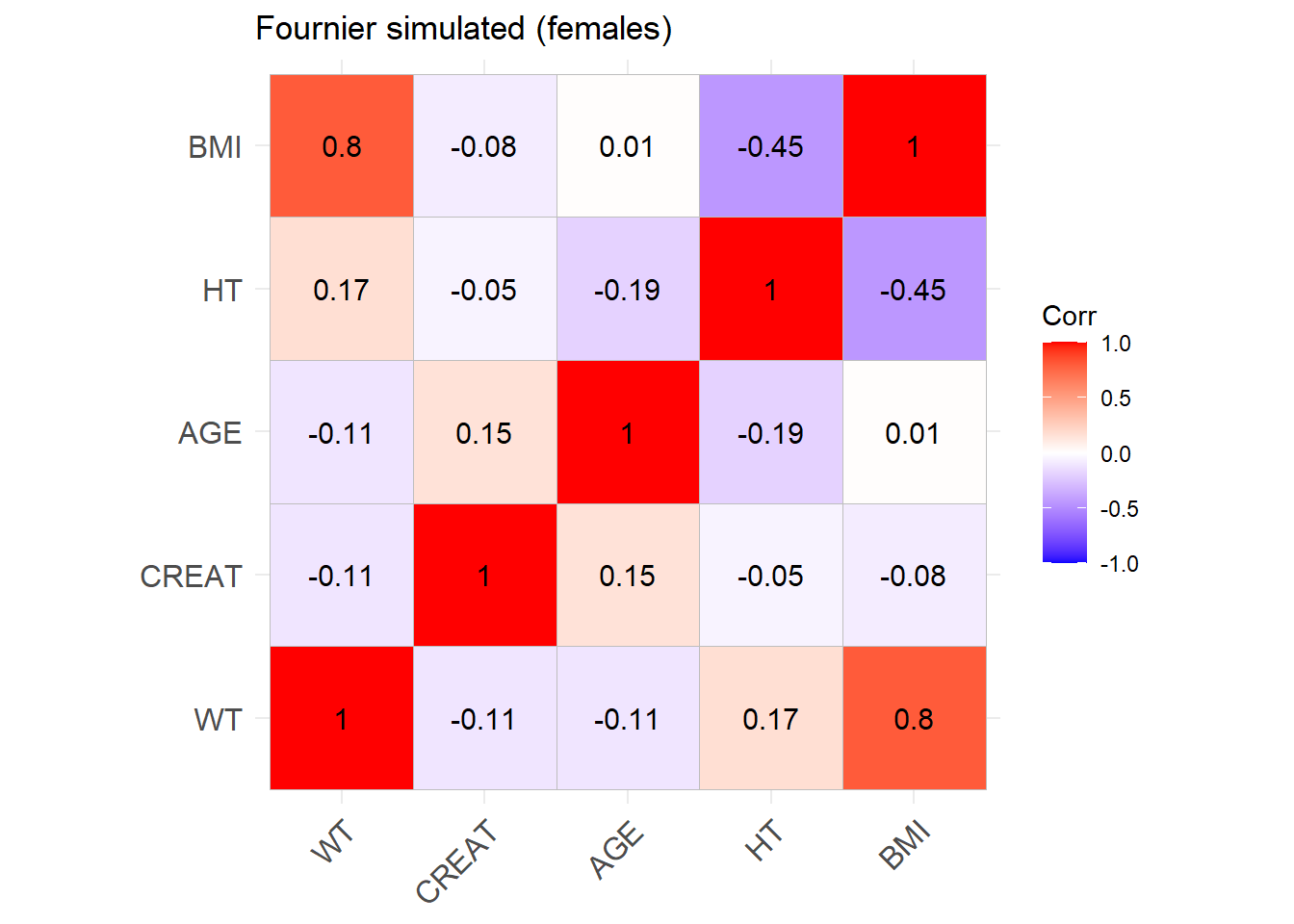
Fournier_F <-ggcorrplot(cor_sim_F, lab =TRUE, title ="Fournier simulated (females)")Fournier_F
Show the code
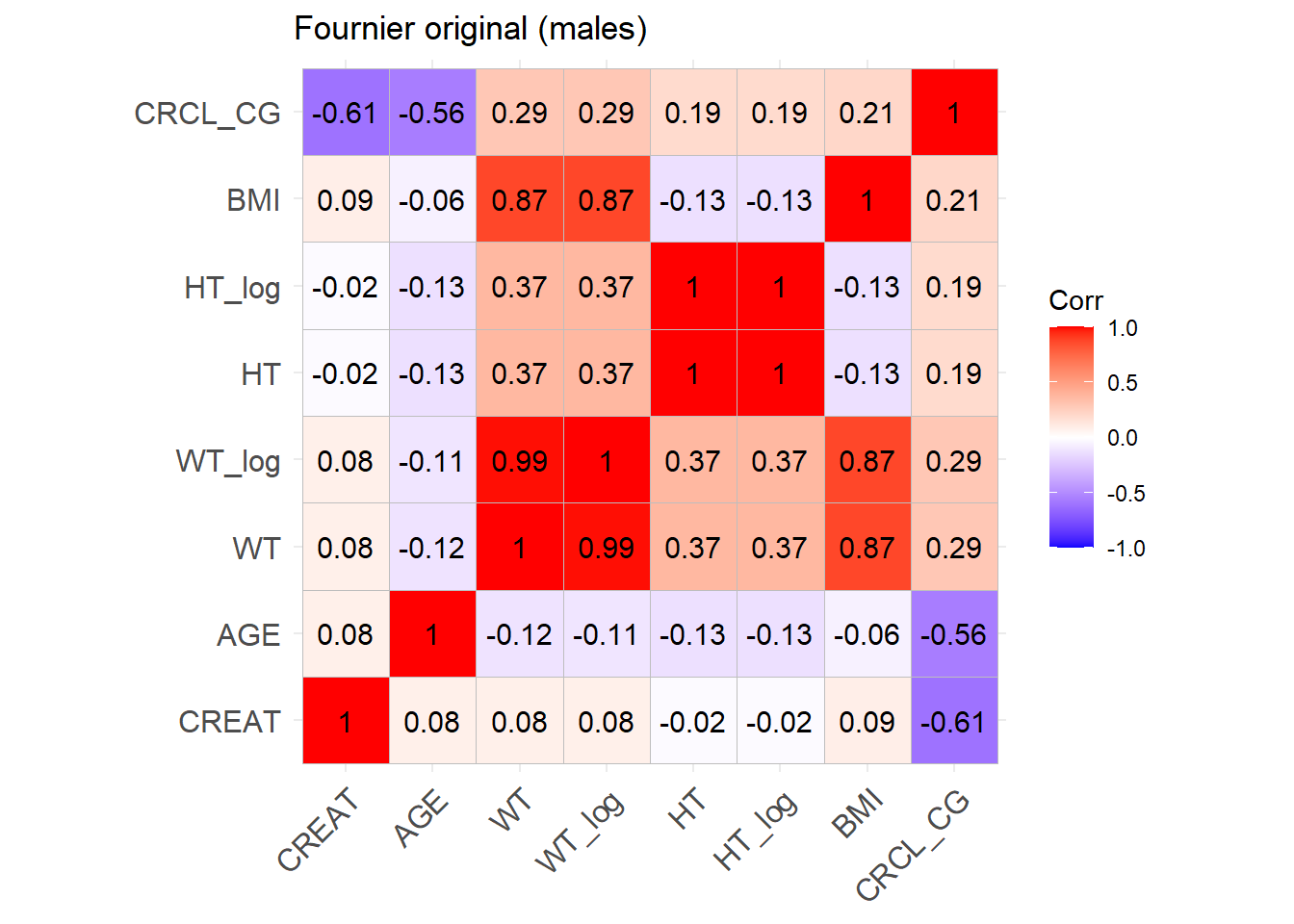
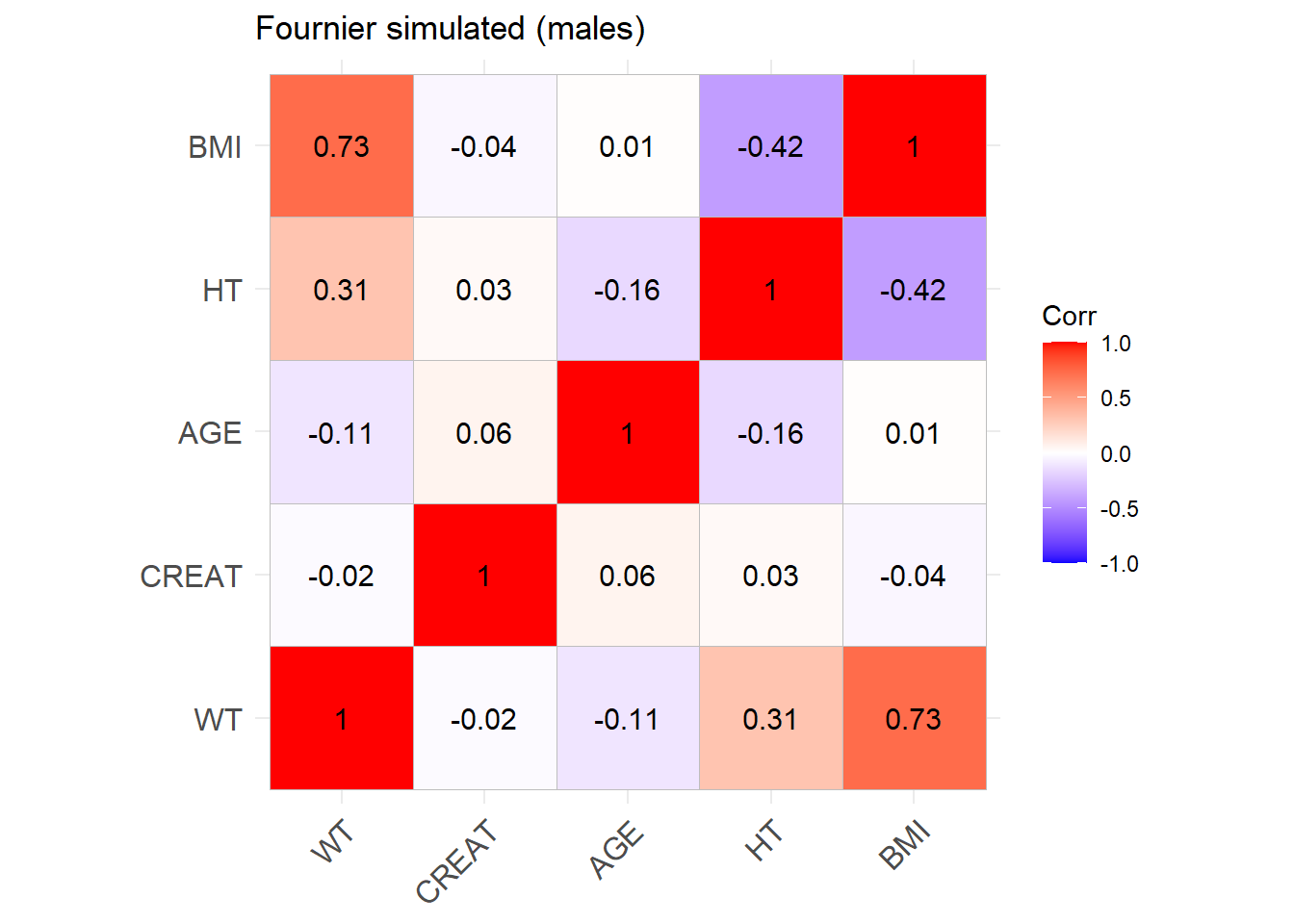
ggcorrplot(cor_matrix_Fournier_M, lab =TRUE, title ="Fournier original (males)")
Show the code
Fournier_M <-ggcorrplot(cor_sim_M, lab =TRUE, title ="Fournier simulated (males)")Fournier_M
Patients are obese, but otherwise healthy, meaning that they are not in intensive care and not burn victims. They are all obese (BMI > 30 kg/m^2). Creatinine clearance is calculated based on the MDRD equation. Thus for all patients ICU = 0, BURN = 0, OBESE=1.
For WT, BMI and CRCL here are the data from the paper :
ggcorrplot(cor_matrix_Mellon_M, lab =TRUE, title ="Sex: male")
Mellon is different from the other papers as CRCL is given as ml/min/1.73m^{2} based on the MDRD equation, and instead of Q1 and Q3, the minimum and maxiumum of the covariates is given (apart from BMI). Another particularity is that due to the particularity of the subjects (obesity), the distribution of body weight is positively (right) skewed. Positively skewed distribution is relatively rare, so it is not easy to find a distribution function to describe it. Beta distribution needs scaling the data between 0 and 1. and 4 parameter stable distribution et gamma distribution have several parameters that need to be defined, and in the absence of the original data, it is not possible to estimate these parameters.
Then, based on the BMI and WT, the height (HT) is calculated to be able to calculate the body surface area (BSA). CRCL is reconverted to serum creatinine (CREAT) based on the MDRD equation.
Show the code
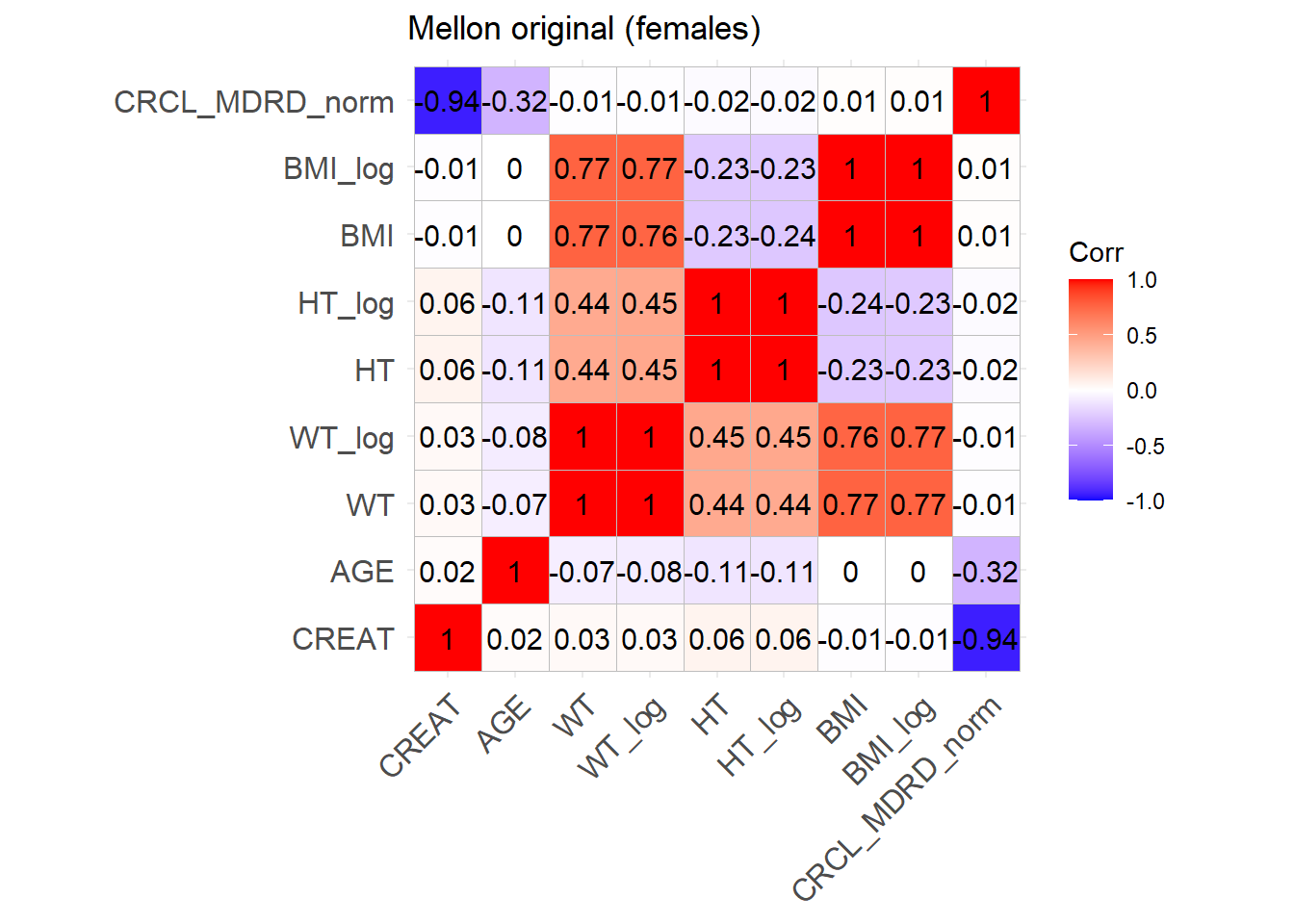
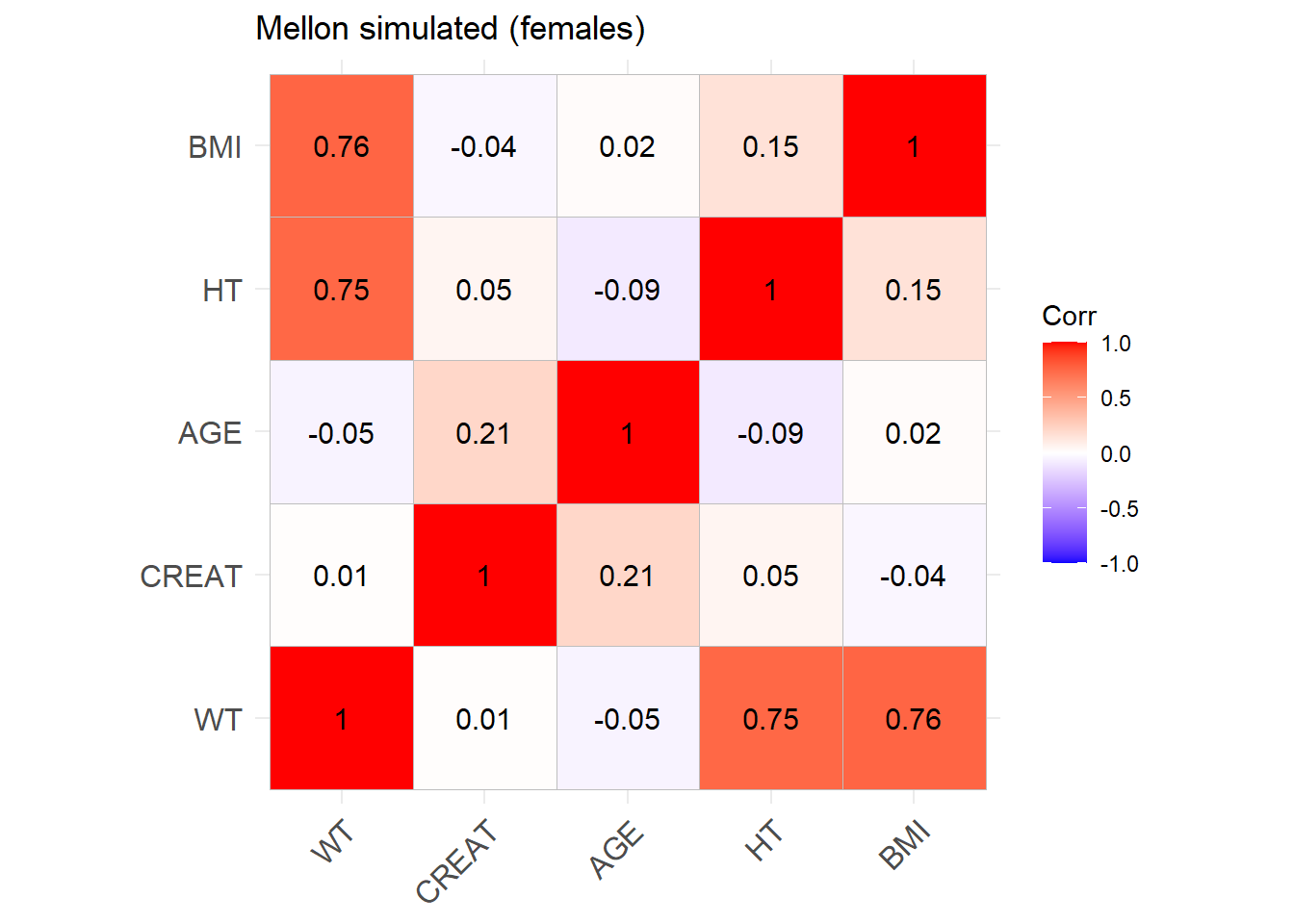
reconvert_MDRD <-function(AGE, CRCL, SEX) {# Mutliply by 0.85 for females sex_factor <-ifelse(SEX ==0, 1, 0.742)# Calculate DFG CREAT <- (CRCL / (175* (AGE^(-0.203)) * sex_factor))^(-1/1.154)return(CREAT)}sim_cov_mellon$CREAT <-mapply(reconvert_MDRD, sim_cov_mellon$AGE, sim_cov_mellon$CRCL, sim_cov_mellon$SEX)sim_cov_mellon <- sim_cov_mellon %>%mutate(HT =sqrt(WT/BMI) *100, # mutliplied by 100 to convert m to cmBSA = (WT^0.425* (HT^0.725) *0.007184),OBESE =ifelse(BMI >30, 1, 0) ) %>% dplyr::select(Paper, ID_within_paper, ICU, BURN, OBESE, CREAT, WT, BSA, BMI, AGE, SEX, HT)# Calculate the simulated correlation matrices separately for the two sexes to compare with the originalsim_cov_mellon_M <- sim_cov_mellon %>%filter(SEX ==0)sim_cov_mellon_F <- sim_cov_mellon %>%filter(SEX ==1)cor_sim_M <-cor(sim_cov_mellon_M %>% dplyr::select(WT, CREAT, AGE, HT, BMI), use ="complete.obs")cor_sim_F <-cor(sim_cov_mellon_F %>% dplyr::select(WT, CREAT, AGE, HT, BMI), use ="complete.obs")ggcorrplot(cor_matrix_Mellon_F, lab =TRUE, title ="Mellon original (females)")
Show the code
Mellon_F <-ggcorrplot(cor_sim_F, lab =TRUE, title ="Mellon simulated (females)")Mellon_F
Show the code
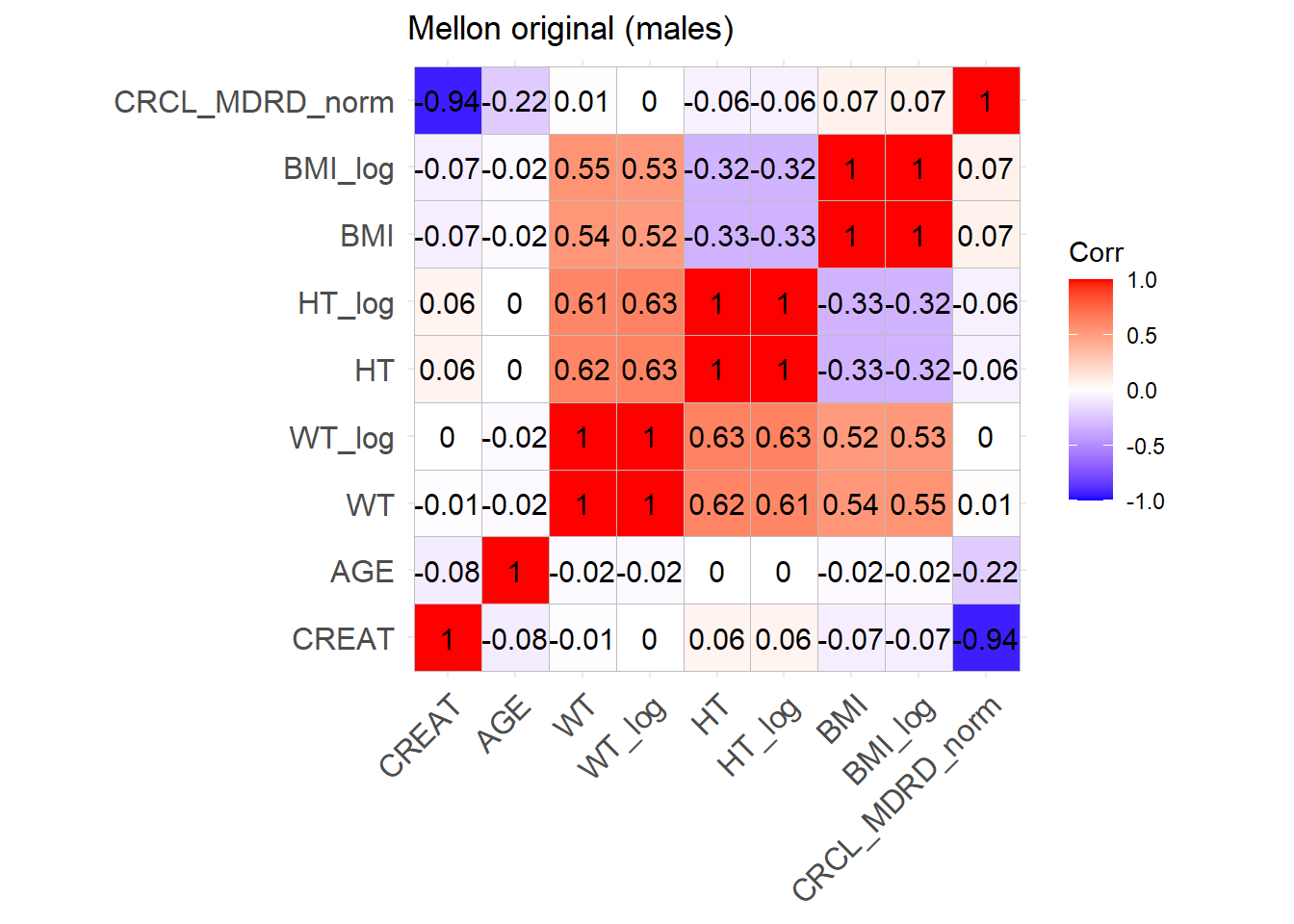
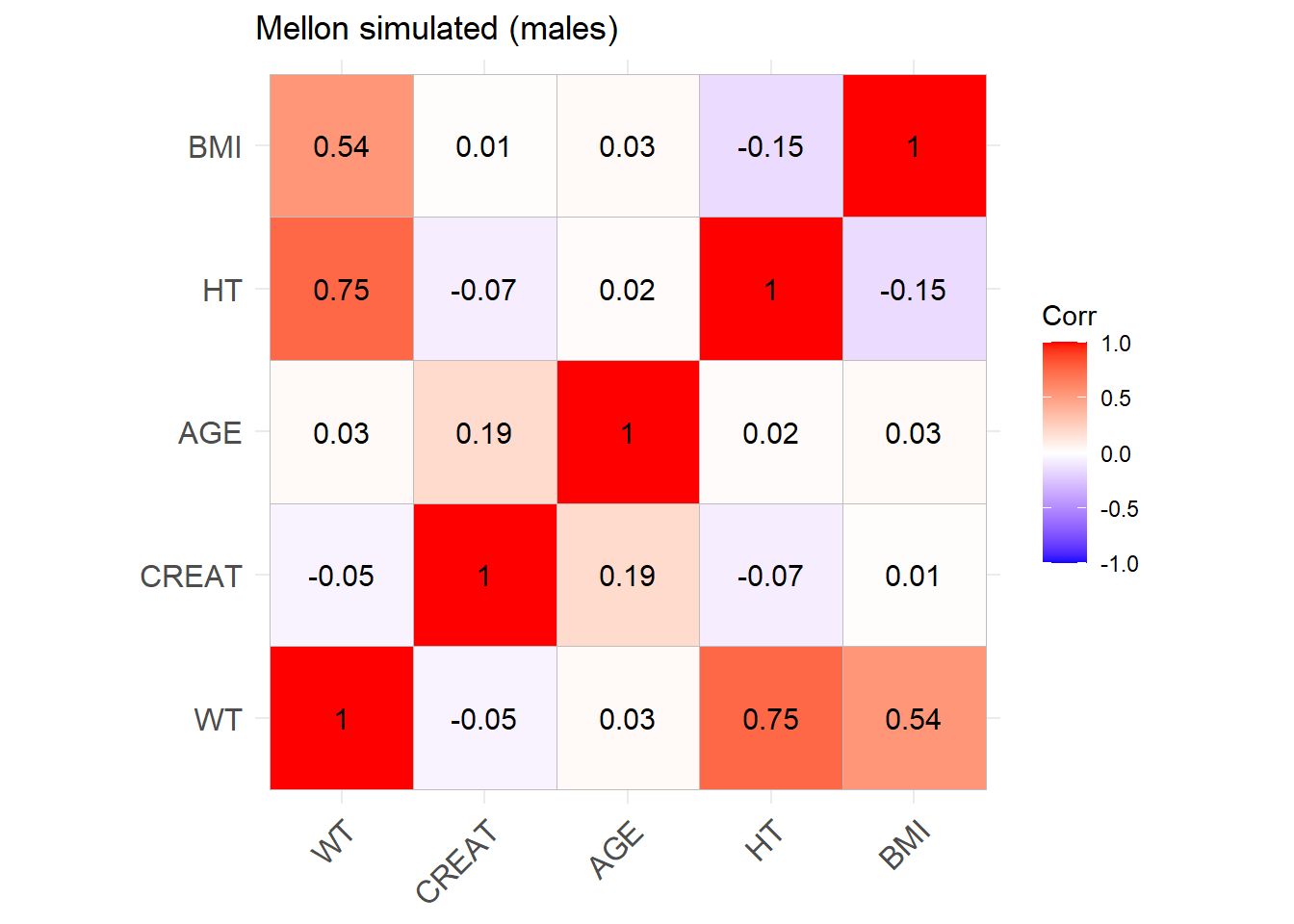
ggcorrplot(cor_matrix_Mellon_M, lab =TRUE, title ="Mellon original (males)")
Show the code
Mellon_M <-ggcorrplot(cor_sim_M, lab =TRUE, title ="Mellon simulated (males)")Mellon_M
All patients are ICU patients with endocarditis. They are not considered to be burn victims or obese. Creatinine clearance was calculated using the CKD-EPI equation. Thus for all patients ICU = 1, BURN = 0 and OBESE=0. In this paper, the distribution of serum creatinine is given (in micromol/L), so it can be directly simulated instead of reconverting CRCL. The proportion of males is 0.794.
For WT and CRCL here are the data from the paper :
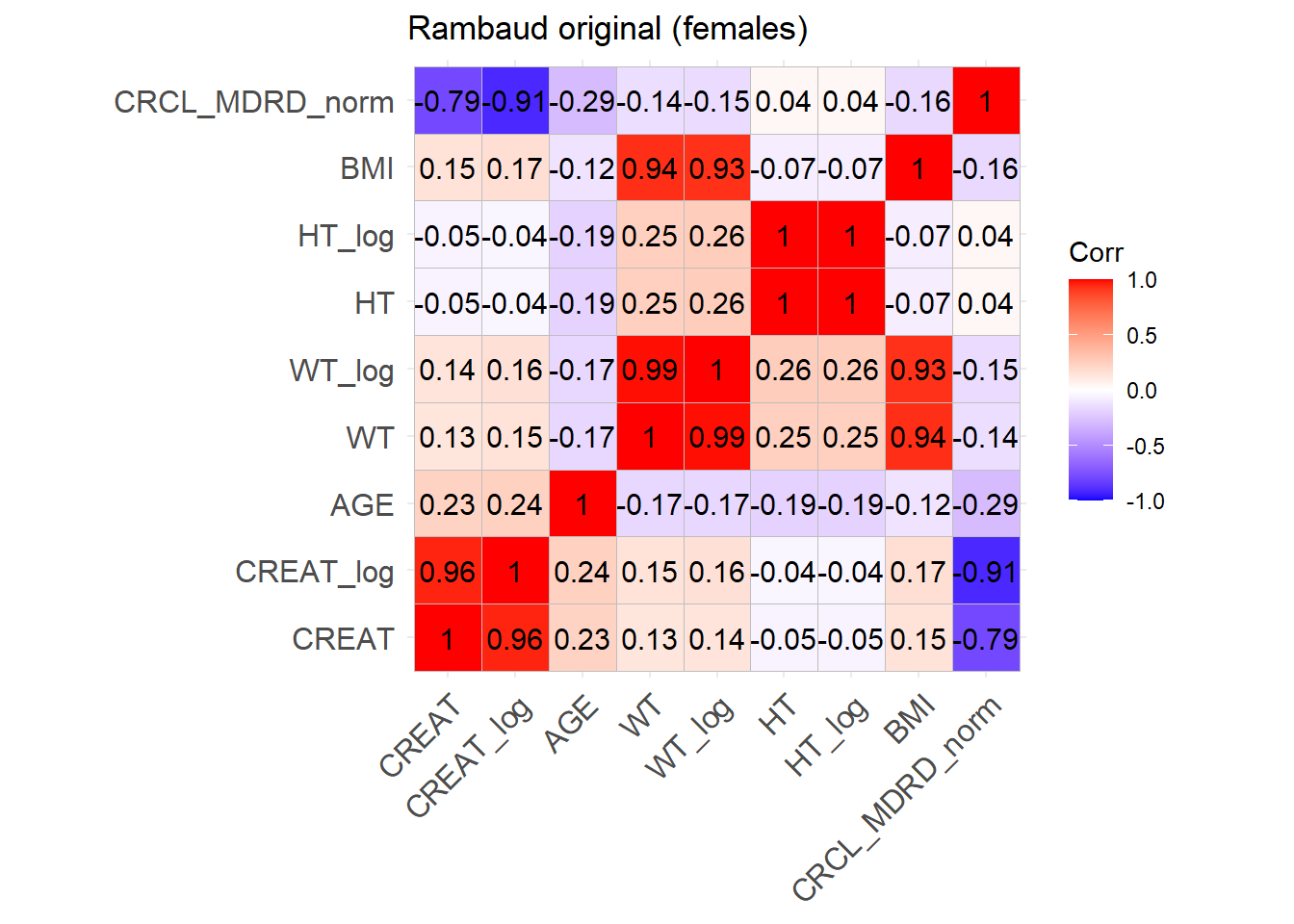
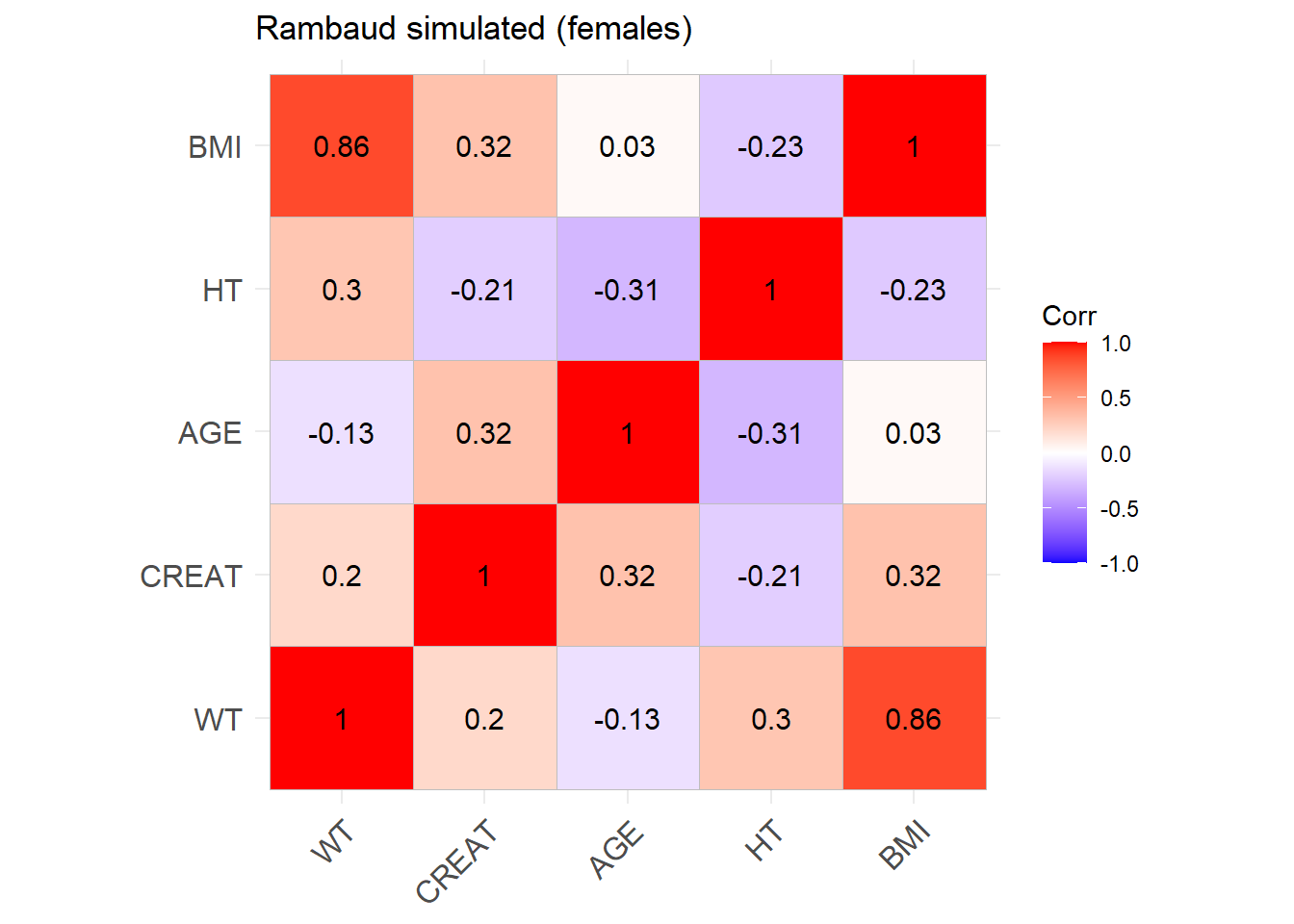
sim_cov_rambaud <- sim_cov_rambaud %>%mutate(BSA = (WT^0.425* (HT^0.725) *0.007184),CREAT = CREAT/88.4,BMI = WT / (HT/100)^2,OBESE =ifelse(BMI >30, 1, 0) ) %>% dplyr::select(Paper, ID_within_paper, ICU, BURN, OBESE, CREAT, WT, BSA, BMI, AGE, SEX, HT)# Calculate the simulated correlation matrices separately for the two sexes to compare with the originalsim_cov_rambaud_M <- sim_cov_rambaud %>%filter(SEX ==0)sim_cov_rambaud_F <- sim_cov_rambaud %>%filter(SEX ==1)cor_sim_M <-cor(sim_cov_rambaud_M %>% dplyr::select(WT, CREAT, AGE, HT, BMI), use ="complete.obs")cor_sim_F <-cor(sim_cov_rambaud_F %>% dplyr::select(WT, CREAT, AGE, HT, BMI), use ="complete.obs")ggcorrplot(cor_matrix_Rambaud_F, lab =TRUE, title ="Rambaud original (females)")
Show the code
Rambaud_F <-ggcorrplot(cor_sim_F, lab =TRUE, title ="Rambaud simulated (females)")Rambaud_F
Show the code
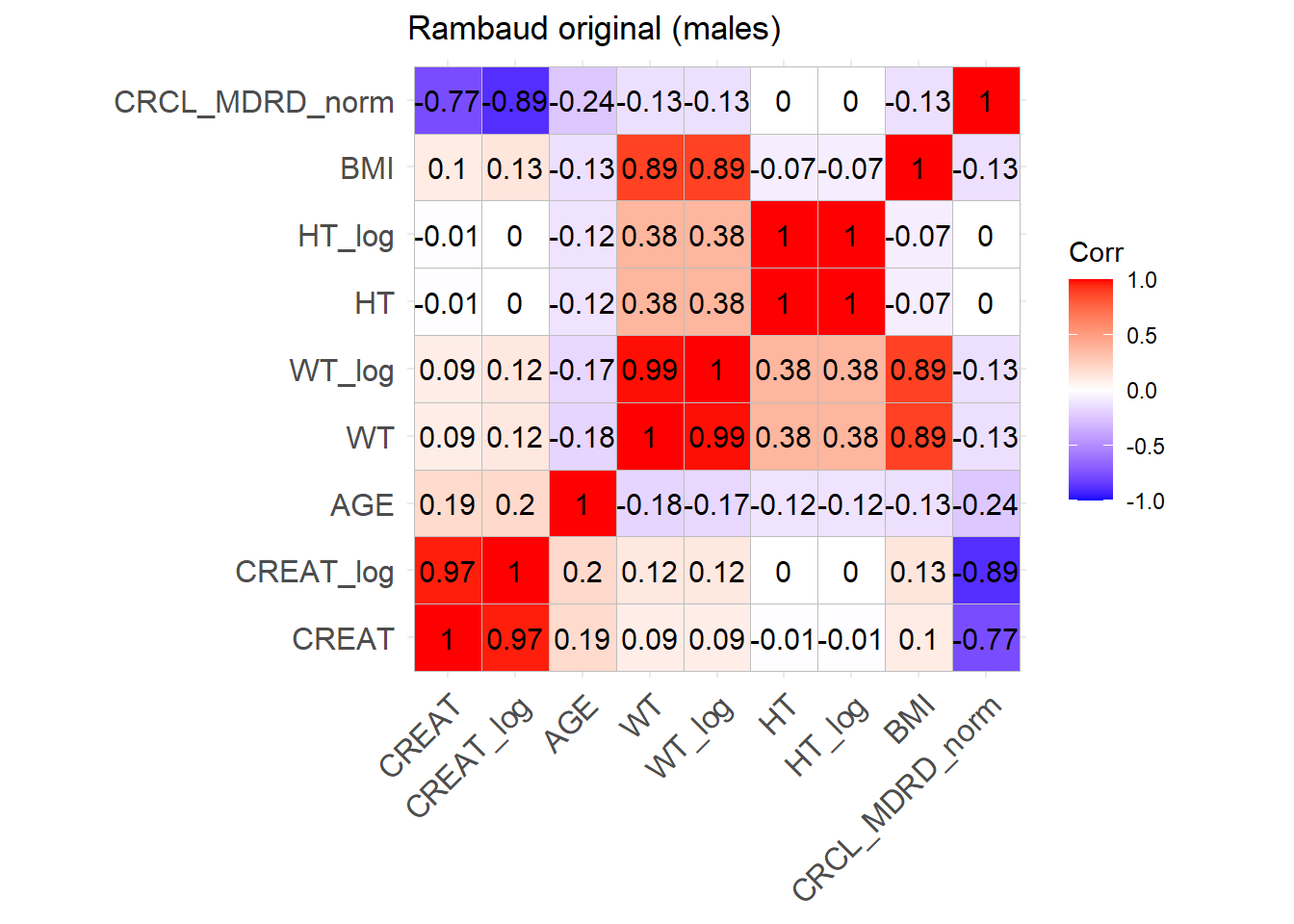
ggcorrplot(cor_matrix_Rambaud_M, lab =TRUE, title ="Rambaud original (males)")
Show the code
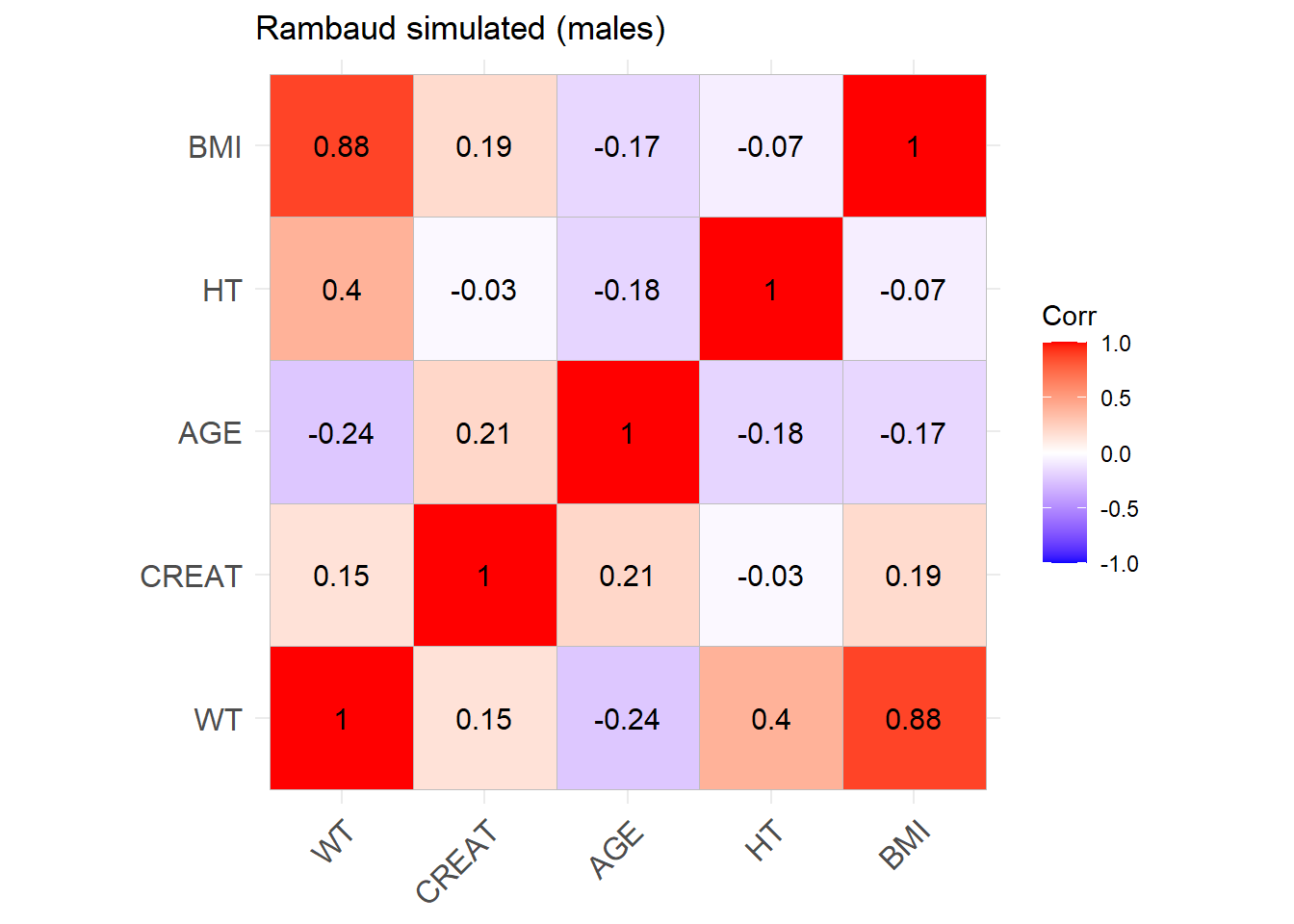
Rambaud_M <-ggcorrplot(cor_sim_M, lab =TRUE, title ="Rambaud simulated (males)")Rambaud_M
5.7 Final covariate table
Make the final covariate dataset with 2500 sets of covariates in a way that in each 100 sets, we have 25-25 from each covariate’s cohort, as later, each dosing regimen will be simulated for 100 sets of covariates, and it is important that the 4 cohorts are equally represented.
Also, for the concentration simulation part, we have to know before applying the models, if a patient needs a different regiment due to his renal failure or not. That is why an additional IR column is added where 1 indicates a renal failure patient who needs a dose adjustement. For Carlier, the MDRD equation is used, and for Fournier, the Cockroft and Gault. For Mellon and Rambaud, all patients have 0 in the IR column, as it is not explicited in the articles that a dose adjustement was applied to renal failure patients.
Show the code
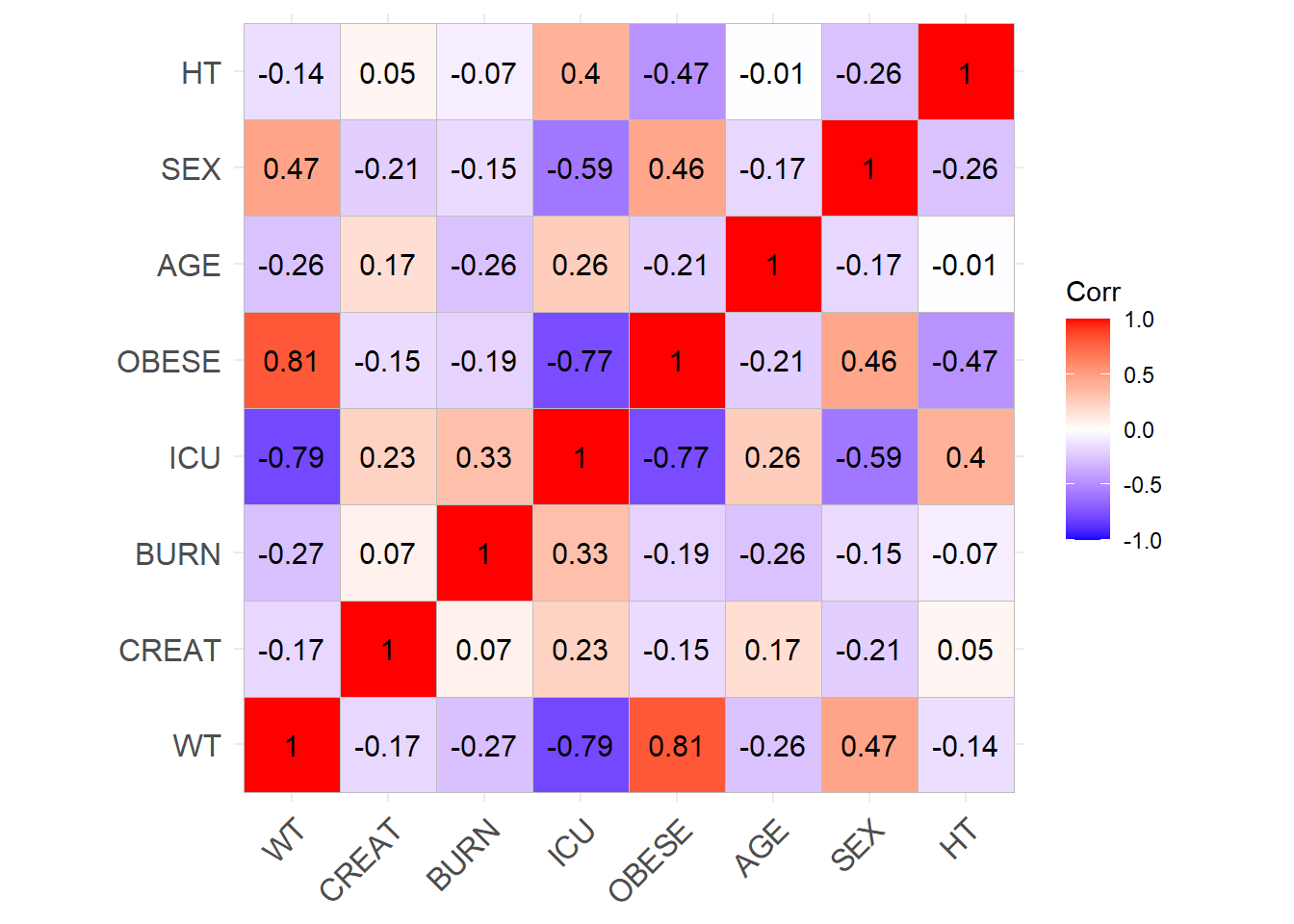
# Patchwork simulated correlation plotscorr_simulated <- (Carlier_F + Fournier_F + Mellon_F + Rambaud_F + Carlier_M + Fournier_M + Mellon_M + Rambaud_M) +plot_layout(ncol =4, nrow =2, byrow =TRUE)ggsave(filename =here("Figures/S5.jpg"),plot = corr_simulated,width =14, height =8, dpi =300)# Row-bind the datasets to have 25 subjects from each in a sample of 100datasets <-list(sim_cov_carlier, sim_cov_fournier, sim_cov_mellon, sim_cov_rambaud)interleave_rows <-function(datasets, chunk_size) { n_chunks <-nrow(datasets[[1]]) / chunk_size interleaved <-do.call(rbind, lapply(1:n_chunks, function(i) {do.call(rbind, lapply(datasets, function(dataset) { dataset[((i -1) * chunk_size +1):(i * chunk_size), ] })) }))return(interleaved)}COV <-interleave_rows(datasets, chunk_size =25)# Convert Paper column to MODEL_COHORT column which indicates the model that is used to simulated the covariatesCOV <- COV %>%mutate(MODEL_COHORT =case_when( Paper =="Carlier_2013"~"CARLIER", Paper =="Fournier_2018"~"FOURNIER", Paper =="Mellon_2020"~"MELLON", Paper =="Rambaud_2020"~"RAMBAUD") )# Adding IDCOV$ID <-seq(1:2500)# CRCL calculation functionscalculate_MDRD <-function(AGE, CREAT, SEX) {# Mutliply by 0.742 for females sex_factor <-ifelse(SEX ==0, 1, 0.742) eGFR <-175* (CREAT^(-1.154)) * AGE^(-0.203) * sex_factorreturn(eGFR)}calculate_CG <-function(AGE, CREAT, SEX, WT) { sex_factor <-ifelse(SEX ==0, 1, 0.85) eGFR <- ((140- AGE) * WT * sex_factor) / (CREAT *72)return(eGFR)}# Add 1 for dose adjustement for CRCL < 30 mL/min for Carlier and FournierCOV <- COV %>%rowwise() %>%mutate(CRCL =case_when( MODEL_COHORT =="CARLIER"~calculate_MDRD(AGE, CREAT, SEX) * (BSA /1.73), MODEL_COHORT =="FOURNIER"~calculate_CG(AGE, CREAT, SEX, WT),TRUE~NA_real_ ),IR =case_when( MODEL_COHORT =="CARLIER"& CRCL <30~1, MODEL_COHORT =="FOURNIER"& CRCL <30~1, MODEL_COHORT %in%c("MELLON", "RAMBAUD") ~0,TRUE~0 ) ) %>%ungroup()COV <- COV %>% dplyr::select(ID, MODEL_COHORT, WT, CREAT, BURN, ICU, OBESE, BSA, AGE, SEX, HT, IR)# Export to csvwrite.csv(COV, here("Data/COV.csv"), quote = F, row.names = F)# Check correlation (Pearson)cor_sim <-cor(COV %>% dplyr::select(WT, CREAT, BURN, ICU, OBESE, AGE, SEX, HT), use ="complete.obs")ggcorrplot(cor_sim, lab =TRUE)
Carlier, Mieke, Michaël Noë, Jan J De Waele, Veronique Stove, Alain G Verstraete, Jeffrey Lipman, and Jason A Roberts. 2013. “Population Pharmacokinetics and Dosing Simulations of Amoxicillin/Clavulanic Acid in Critically Ill Patients.”J. Antimicrob. Chemother. 68 (11): 2600–2608.
Fournier, Anne, Sylvain Goutelle, Yok-Ai Que, Philippe Eggimann, Olivier Pantet, Farshid Sadeghipour, Pierre Voirol, and Chantal Csajka. 2018. “Population Pharmacokinetic Study of Amoxicillin-Treated Burn Patients Hospitalized at a Swiss Tertiary-Care Center.”Antimicrobial Agents and Chemotherapy 62 (9): e00505–18. https://doi.org/10.1128/AAC.00505-18.
Johnson, Alistair E W, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J Pollard, et al. 2023. “MIMIC-IV, a Freely Accessible Electronic Health Record Dataset.”Sci. Data 10 (1): 1.
Mellon, G, K Hammas, C Burdet, X Duval, C Carette, N El-Helali, L Massias, F Mentré, S Czernichow, and A -C Crémieux. 2020. “Population Pharmacokinetics and Dosing Simulations of Amoxicillin in Obese Adults Receiving Co-Amoxiclav.”Journal of Antimicrobial Chemotherapy 75 (12): 3611–18. https://doi.org/10.1093/jac/dkaa368.
Rambaud, Antoine, Benjamin Jean Gaborit, Colin Deschanvres, Paul Le Turnier, Raphaël Lecomte, Nathalie Asseray-Madani, Anne-Gaëlle Leroy, et al. 2020. “Development and Validation of a Dosing Nomogram for Amoxicillin in Infective Endocarditis.”The Journal of Antimicrobial Chemotherapy 75 (10): 2941–50. https://doi.org/10.1093/jac/dkaa232.